 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Convolutional LSTM Network for Referring Image Segmentation
Paper and Code
Jan 30, 2020
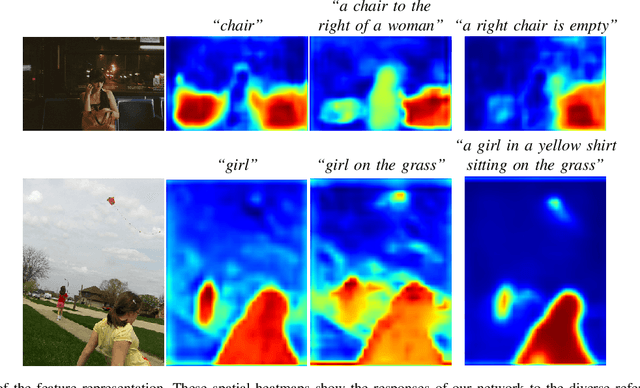
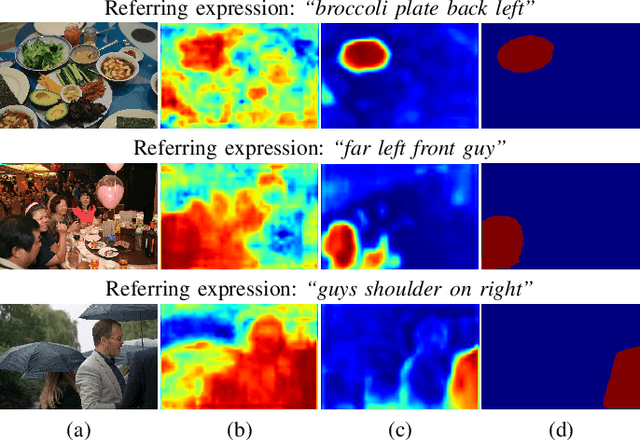
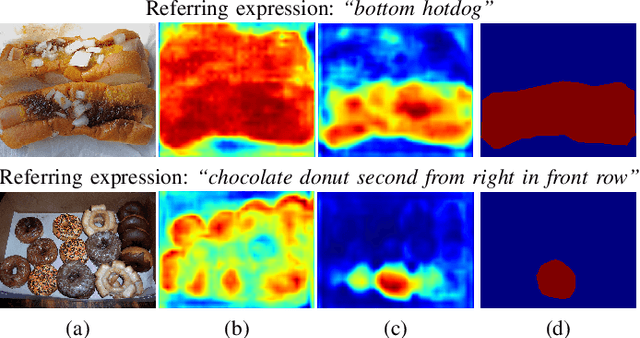
We consider referring image segmentation. It is a problem at the intersection of computer vision and natural language understanding. Given an input image and a referring expression in the form of a natural language sentence, the goal is to segment the object of interest in the image referred by the linguistic query. To this end, we propose a dual convolutional LSTM (ConvLSTM) network to tackle this problem. Our model consists of an encoder network and a decoder network, where ConvLSTM is used in both encoder and decoder networks to capture spatial and sequential information. The encoder network extracts visual and linguistic features for each word in the expression sentence, and adopts an attention mechanism to focus on words that are more informative in the multimodal interaction. The decoder network integrates the features generated by the encoder network at multiple levels as its input and produces the final precise segmentation mask. Experimental results on four challenging datasets demonstrate that the proposed network achieves superior segmentation performance compared with other state-of-the-art methods.