 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Sentiment Analysis for Code-mixed Data
Paper and Code
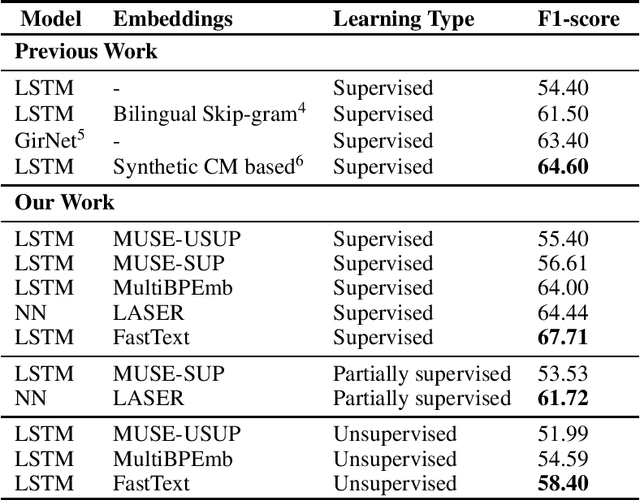
Code-mixing is the practice of alternating between two or more languages. Mostly observed in multilingual societies, its occurrence is increasing and therefore its importance. A major part of sentiment analysis research has been monolingual, and most of them perform poorly on code-mixed text. In this work, we introduce methods that use different kinds of multilingual and cross-lingual embeddings to efficiently transfer knowledge from monolingual text to code-mixed text for sentiment analysis of code-mixed text. Our methods can handle code-mixed text through a zero-shot learning. Our methods beat state-of-the-art on English-Spanish code-mixed sentiment analysis by absolute 3\% F1-score. We are able to achieve 0.58 F1-score (without parallel corpus) and 0.62 F1-score (with parallel corpus) on the same benchmark in a zero-shot way as compared to 0.68 F1-score in supervised settings. Our code is publicly available.