Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFurther Boosting BERT-based Models by Duplicating Existing Layers: Some Intriguing Phenomena inside BERT
Paper and Code
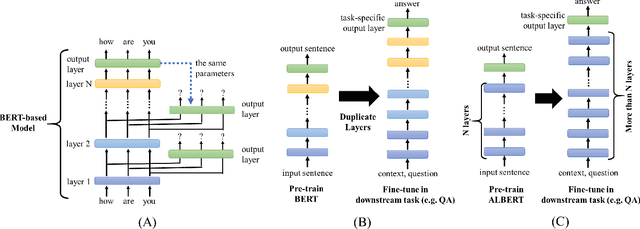
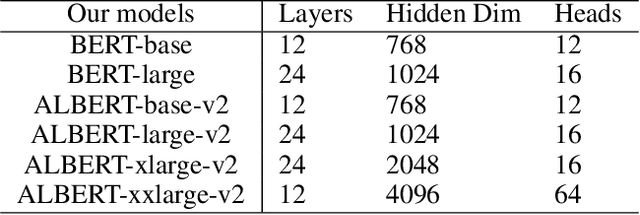
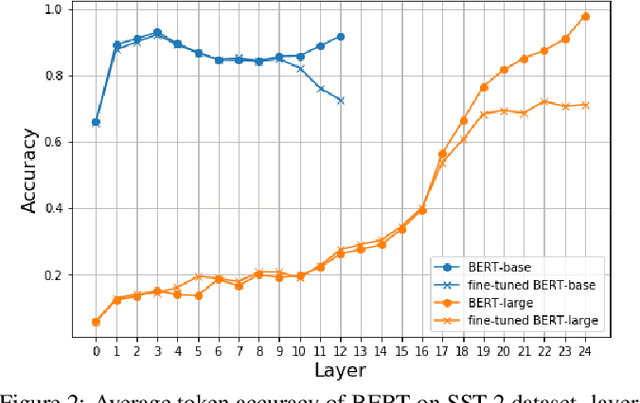
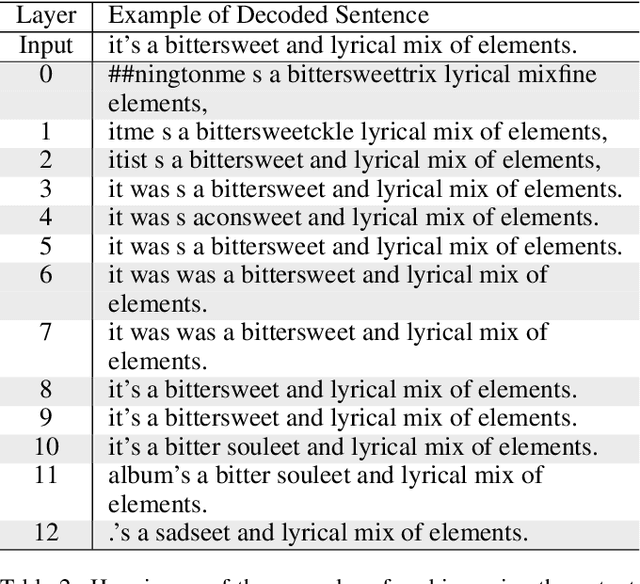
Although Bidirectional Encoder Representations from Transformers (BERT) have achieved tremendous success in many natural language processing (NLP) tasks, it remains a black box, so much previous work has tried to lift the veil of BERT and understand the functionality of each layer. In this paper, we found that removing or duplicating most layers in BERT would not change their outputs. This fact remains true across a wide variety of BERT-based models. Based on this observation, we propose a quite simple method to boost the performance of BERT. By duplicating some layers in the BERT-based models to make it deeper (no extra training required in this step), they obtain better performance in the down-stream tasks after fine-tuning.
* 7 pages, 8 figures, 6 tables
View paper on