 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
Paper and Code


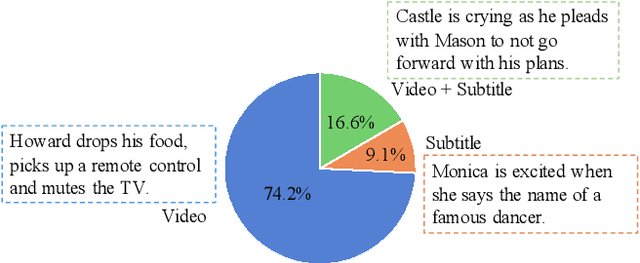

We introduce a new multimodal retrieval task - TV show Retrieval (TVR), in which a short video moment has to be localized from a large video (with subtitle) corpus, given a natural language query. Different from previous moment retrieval tasks dealing with videos only, TVR requires the system to understand both the video and the associated subtitle text, making it a more realistic task. To support the study of this new task, we have collected a large-scale, high-quality dataset consisting of 108,965 queries on 21,793 videos from 6 TV shows of diverse genres, where each query is associated with a tight temporal alignment. Strict qualification and post-annotation verification tests are applied to ensure the quality of the collected data. We present several baselines and a novel Cross-modal Moment Localization (XML) modular network for this new dataset and task. The proposed XML model surpasses all presented baselines by a large margin and with better efficiency, providing a strong starting point for future work. Extensive analysis experiments also show that incorporating both video and subtitle modules yields better performance than either alone. Lastly, we have also collected additional descriptions for each annotated moment in TVR to form a new multimodal captioning dataset with 262K captions, named the TV show Caption dataset (TVC). Here models need to jointly use the video and subtitle to generate a caption description. Both datasets are publicly available at https://tvr.cs.unc.edu