 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTernary Feature Masks: continual learning without any forgetting
Paper and Code
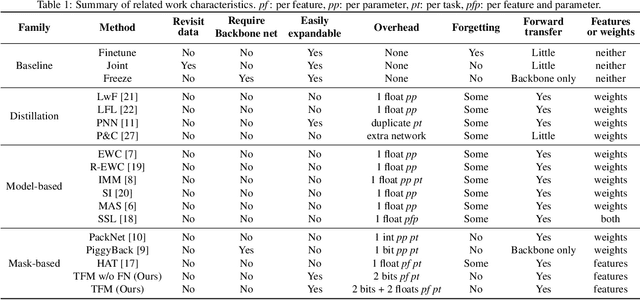
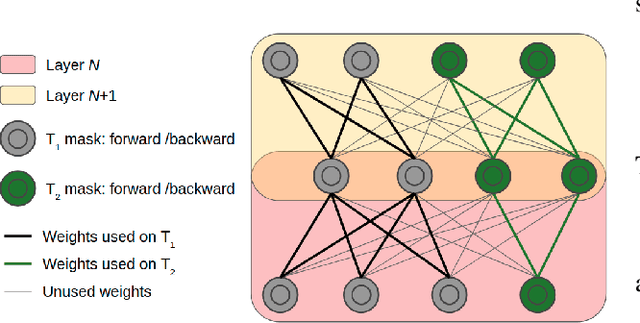
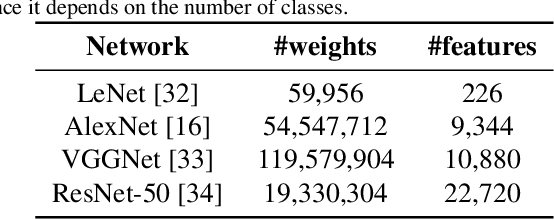
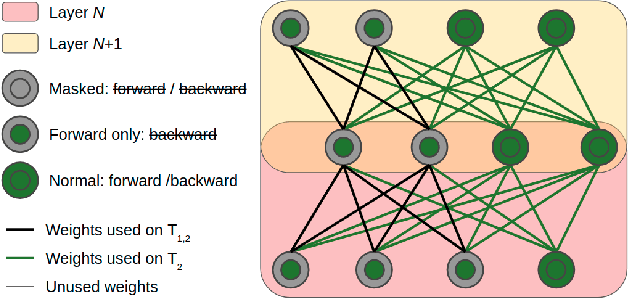
In this paper, we propose an approach without any forgetting to continual learning for the task-aware regime, where at inference the task-label is known. By using ternary masks we can upgrade a model to new tasks, reusing knowledge from previous tasks while not forgetting anything about them. Using masks prevents both catastrophic forgetting and backward transfer. We argue -- and show experimentally -- that avoiding the former largely compensates for the lack of the latter, which is rarely observed in practice. In contrast to earlier works, our masks are applied to the features (activations) of each layer instead of the weights. This considerably reduces the number of mask parameters to be added for each new task; with more than three orders of magnitude for most networks. The encoding of the ternary masks into two bits per feature creates very little overhead to the network, avoiding scalability issues. Our masks do not permit any changes to features which are used by previous tasks. As this may be too restrictive to allow learning of new tasks, we add task-specific feature normalization. This way, already learned features can adapt to the current task without changing the behavior of these features for previous tasks. Extensive experiments on several finegrained datasets and ImageNet show that our method outperforms current state-of-the-art while reducing memory overhead in comparison to weight-based approaches.