 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-site fMRI Analysis Using Privacy-preserving Federated Learning and Domain Adaptation: ABIDE Results
Paper and Code
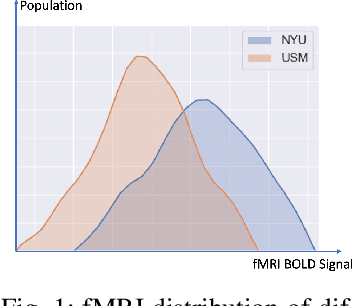
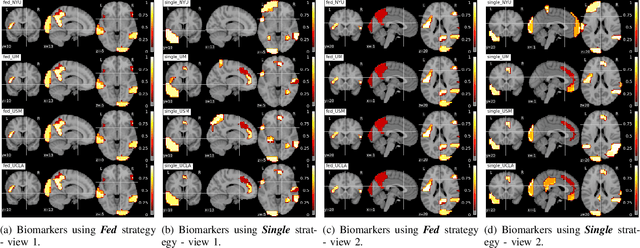
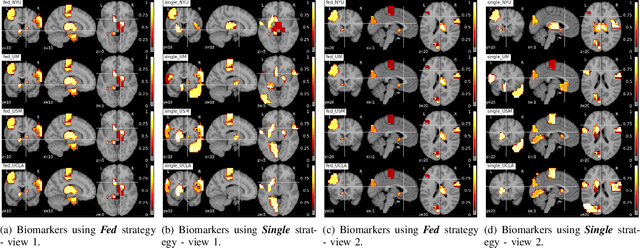
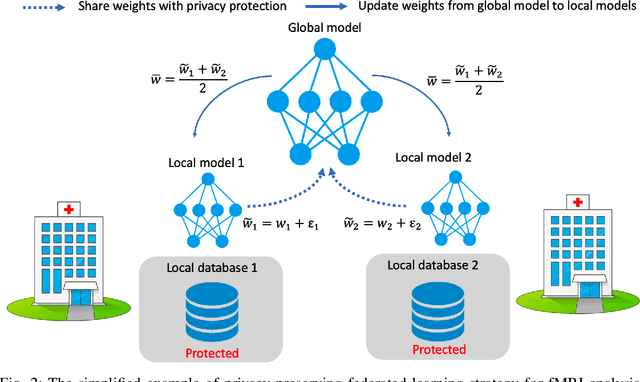
Deep learning models have shown their advantage in many different tasks, including neuroimage analysis. However, to effectively train a high-quality deep learning model, the aggregation of a significant amount of patient information is required. The time and cost for acquisition and annotation in assembling, for example, large fMRI datasets make it difficult to acquire large numbers at a single site. However, due to the need to protect the privacy of patient data, it is hard to assemble a central database from multiple institutions. Federated learning allows for population-level models to be trained without centralizing entities' data by transmitting the global model to local entities, training the model locally, and then averaging the gradients or weights in the global model. However, some studies suggest that private information can be recovered from the model gradients or weights. In this work, we address the problem of multi-site fMRI classification with a privacy-preserving strategy. To solve the problem, we propose a federated learning approach, where a decentralized iterative optimization algorithm is implemented and shared local model weights are altered by a randomization mechanism. Considering the systemic differences of fMRI distributions from different sites, we further propose two domain adaptation methods in this federated learning formulation. We investigate various practical aspects of federated model optimization and compare federated learning with alternative training strategies. Overall, our results demonstrate that it is promising to utilize multi-site data without data sharing to boost neuroimage analysis performance and find reliable disease-related biomarkers. Our proposed pipeline can be generalized to other privacy-sensitive medical data analysis problems.