 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimEx: Express Prediction of Inter-dataset Similarity by a Fleet of Autoencoders
Paper and Code
Jan 14, 2020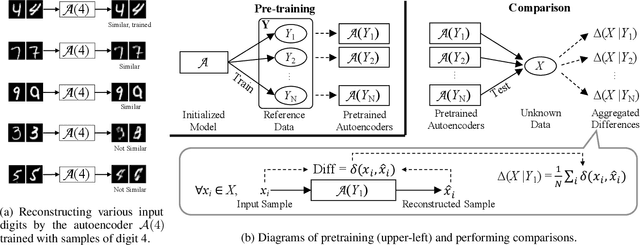


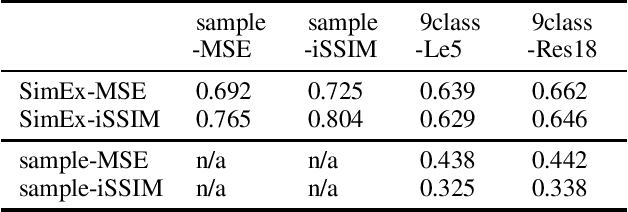
Knowing the similarity between sets of data has a number of positive implications in training an effective model, such as assisting an informed selection out of known datasets favorable to model transfer or data augmentation problems with an unknown dataset. Common practices to estimate the similarity between data include comparing in the original sample space, comparing in the embedding space from a model performing a certain task, or fine-tuning a pretrained model with different datasets and evaluating the performance changes therefrom. However, these practices would suffer from shallow comparisons, task-specific biases, or extensive time and computations required to perform comparisons. We present SimEx, a new method for early prediction of inter-dataset similarity using a set of pretrained autoencoders each of which is dedicated to reconstructing a specific part of known data. Specifically, our method takes unknown data samples as input to those pretrained autoencoders, and evaluate the difference between the reconstructed output samples against their original input samples. Our intuition is that, the more similarity exists between the unknown data samples and the part of known data that an autoencoder was trained with, the better chances there could be that this autoencoder makes use of its trained knowledge, reconstructing output samples closer to the originals. We demonstrate that our method achieves more than 10x speed-up in predicting inter-dataset similarity compared to common similarity-estimating practices. We also demonstrate that the inter-dataset similarity estimated by our method is well-correlated with common practices and outperforms the baselines approaches of comparing at sample- or embedding-spaces, without newly training anything at the comparison time.