 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Domain Adaptation for Text Classification via DistanceNet-Bandits
Paper and Code
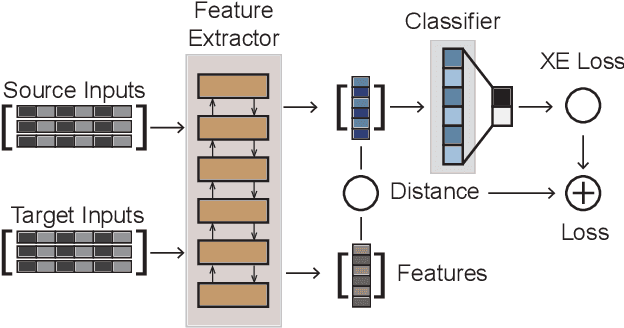
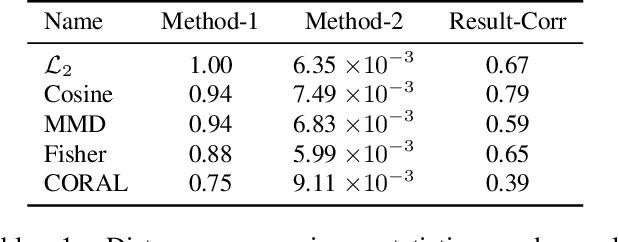
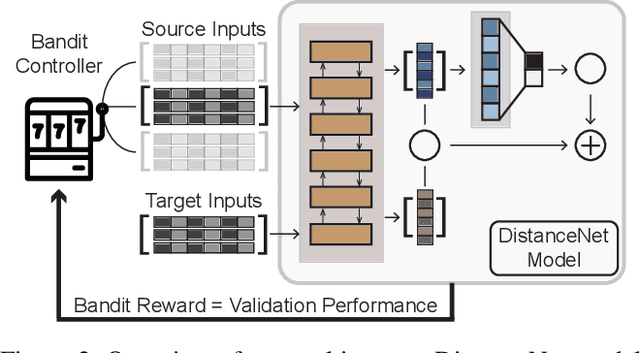

Domain adaptation performance of a learning algorithm on a target domain is a function of its source domain error and a divergence measure between the data distribution of these two domains. We present a study of various distance-based measures in the context of NLP tasks, that characterize the dissimilarity between domains based on sample estimates. We first conduct analysis experiments to show which of these distance measures can best differentiate samples from same versus different domains, and are correlated with empirical results. Next, we develop a DistanceNet model which uses these distance measures, or a mixture of these distance measures, as an additional loss function to be minimized jointly with the task's loss function, so as to achieve better unsupervised domain adaptation. Finally, we extend this model to a novel DistanceNet-Bandit model, which employs a multi-armed bandit controller to dynamically switch between multiple source domains and allow the model to learn an optimal trajectory and mixture of domains for transfer to the low-resource target domain. We conduct experiments on popular sentiment analysis datasets with several diverse domains and show that our DistanceNet model, as well as its dynamic bandit variant, can outperform competitive baselines in the context of unsupervised domain adaptation.