 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHSAN: Multi-Head Self-Attention Network for Visual Semantic Embedding
Paper and Code
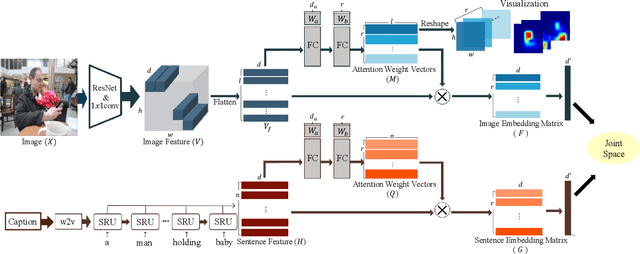
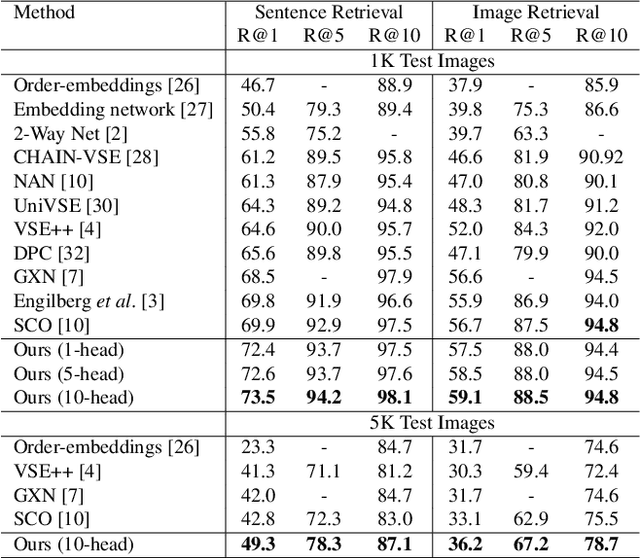
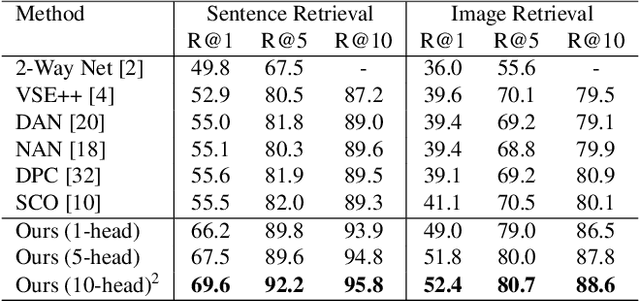

Visual-semantic embedding enables various tasks such as image-text retrieval, image captioning, and visual question answering. The key to successful visual-semantic embedding is to express visual and textual data properly by accounting for their intricate relationship. While previous studies have achieved much advance by encoding the visual and textual data into a joint space where similar concepts are closely located, they often represent data by a single vector ignoring the presence of multiple important components in an image or text. Thus, in addition to the joint embedding space, we propose a novel multi-head self-attention network to capture various components of visual and textual data by attending to important parts in data. Our approach achieves the new state-of-the-art results in image-text retrieval tasks on MS-COCO and Flicker30K datasets. Through the visualization of the attention maps that capture distinct semantic components at multiple positions in the image and the text, we demonstrate that our method achieves an effective and interpretable visual-semantic joint space.