 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphACT: Accelerating GCN Training on CPU-FPGA Heterogeneous Platforms
Paper and Code
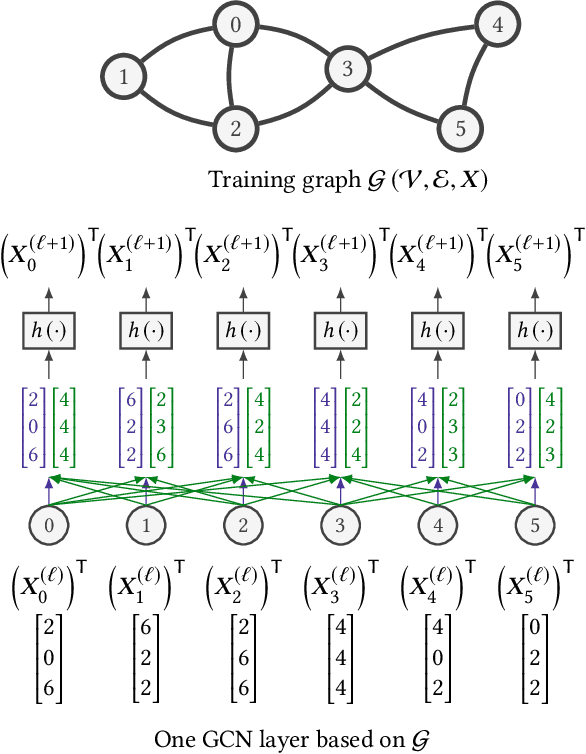
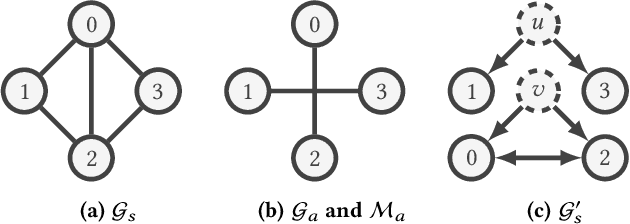
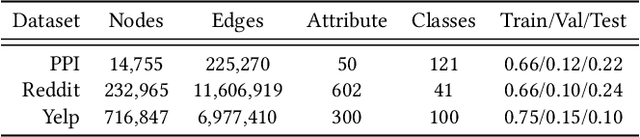
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art deep learning model for representation learning on graphs. It is challenging to accelerate training of GCNs, due to (1) substantial and irregular data communication to propagate information within the graph, and (2) intensive computation to propagate information along the neural network layers. To address these challenges, we design a novel accelerator for training GCNs on CPU-FPGA heterogeneous systems, by incorporating multiple algorithm-architecture co-optimizations. We first analyze the computation and communication characteristics of various GCN training algorithms, and select a subgraph-based algorithm that is well suited for hardware execution. To optimize the feature propagation within subgraphs, we propose a lightweight pre-processing step based on a graph theoretic approach. Such pre-processing performed on the CPU significantly reduces the memory access requirements and the computation to be performed on the FPGA. To accelerate the weight update in GCN layers, we propose a systolic array based design for efficient parallelization. We integrate the above optimizations into a complete hardware pipeline, and analyze its load-balance and resource utilization by accurate performance modeling. We evaluate our design on a Xilinx Alveo U200 board hosted by a 40-core Xeon server. On three large graphs, we achieve an order of magnitude training speedup with negligible accuracy loss, compared with state-of-the-art implementation on a multi-core platform.