 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Goal-Distance Gradient
Paper and Code
Jan 10, 2020
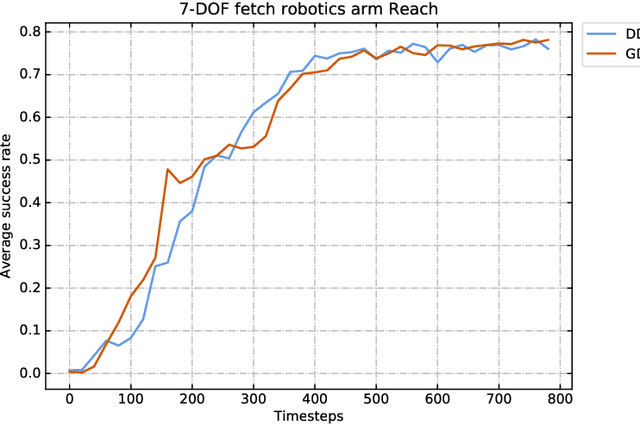
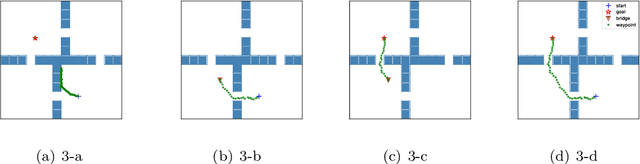
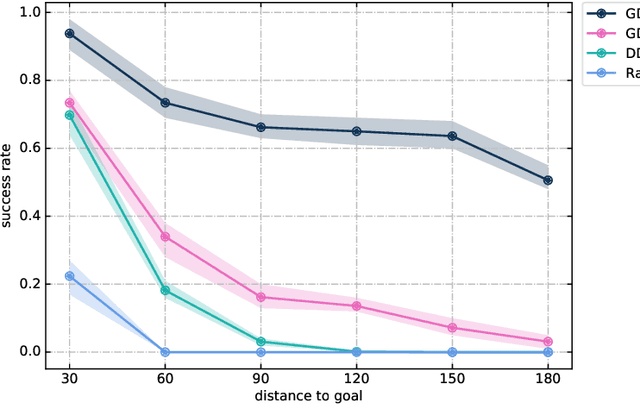
Reinforcement learning usually uses the feedback rewards of environmental to train agents. But the rewards in the actual environment are sparse, and even some environments will not rewards. Most of the current methods are difficult to get good performance in sparse reward or non-reward environments. Although using shaped rewards is effective when solving sparse reward tasks, it is limited to specific problems and learning is also susceptible to local optima. We propose a model-free method that does not rely on environmental rewards to solve the problem of sparse rewards in the general environment. Our method use the minimum number of transitions between states as the distance to replace the rewards of environmental, and proposes a goal-distance gradient to achieve policy improvement. We also introduce a bridge point planning method based on the characteristics of our method to improve exploration efficiency, thereby solving more complex tasks. Experiments show that our method performs better on sparse reward and local optimal problems in complex environments than previous work.