 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Discrete Smoothing for High-Dimensional and Nonlinear Panel Data
Paper and Code
Jan 03, 2020
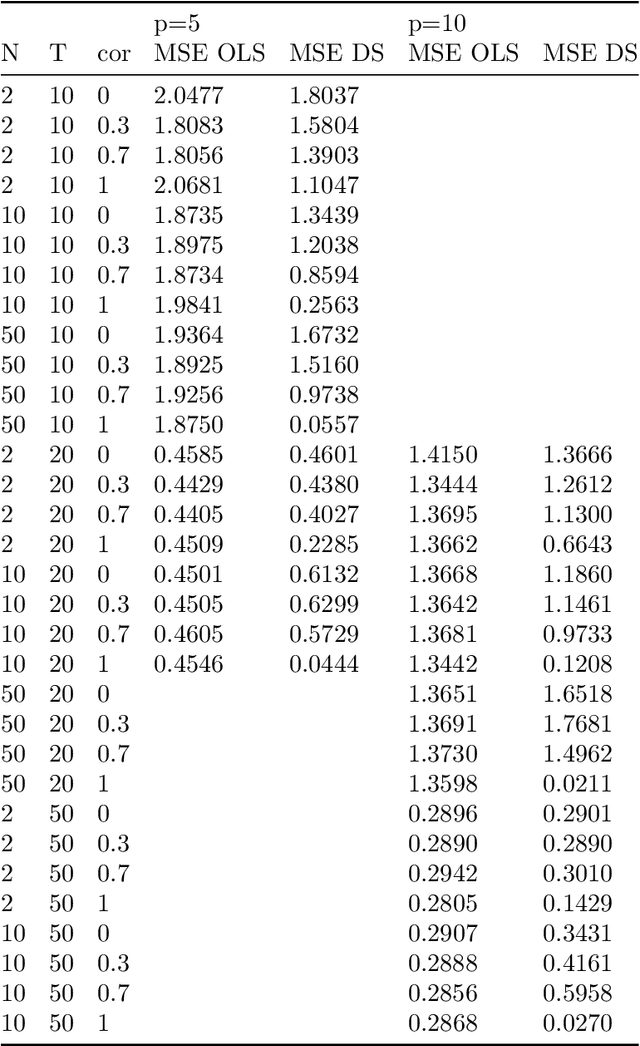
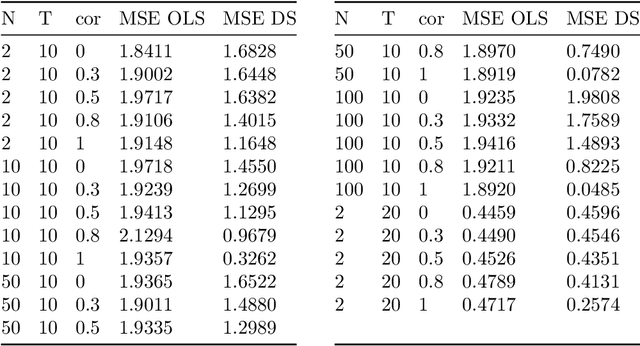
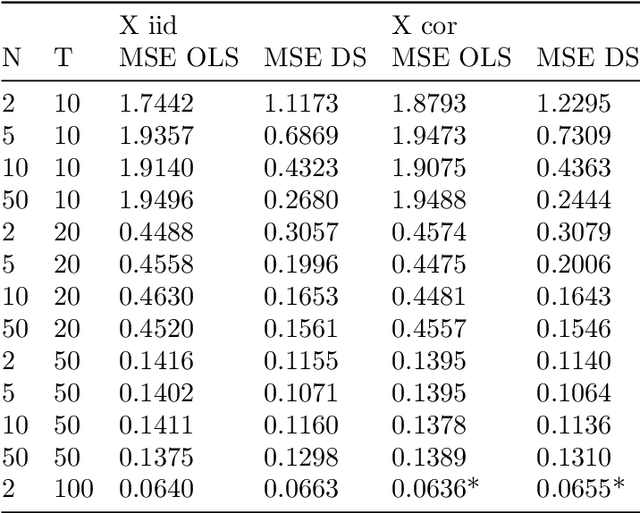
In this paper we develop a data-driven smoothing technique for high-dimensional and non-linear panel data models. We allow for individual specific (non-linear) functions and estimation with econometric or machine learning methods by using weighted observations from other individuals. The weights are determined by a data-driven way and depend on the similarity between the corresponding functions and are measured based on initial estimates. The key feature of such a procedure is that it clusters individuals based on the distance / similarity between them, estimated in a first stage. Our estimation method can be combined with various statistical estimation procedures, in particular modern machine learning methods which are in particular fruitful in the high-dimensional case and with complex, heterogeneous data. The approach can be interpreted as a \textquotedblleft soft-clustering\textquotedblright\ in comparison to traditional\textquotedblleft\ hard clustering\textquotedblright that assigns each individual to exactly one group. We conduct a simulation study which shows that the prediction can be greatly improved by using our estimator. Finally, we analyze a big data set from didichuxing.com, a leading company in transportation industry, to analyze and predict the gap between supply and demand based on a large set of covariates. Our estimator clearly performs much better in out-of-sample prediction compared to existing linear panel data estimators.