 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Q-network
Paper and Code
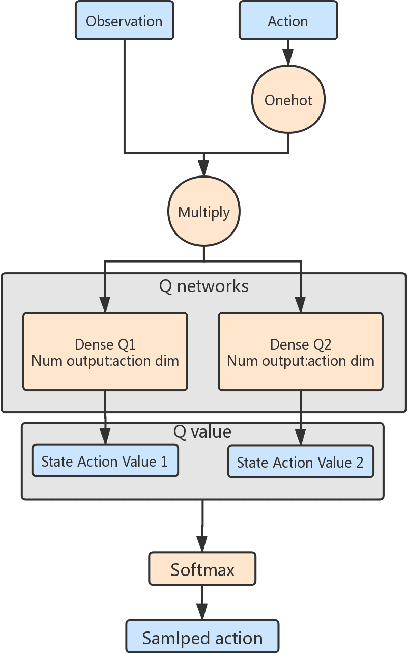
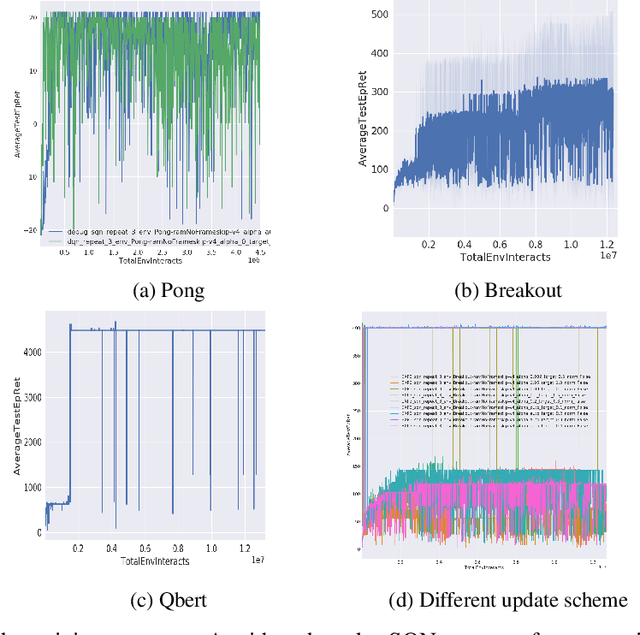
When DQN is announced by deepmind in 2013, the whole world is surprised by the simplicity and promising result, but due to the low efficiency and stability of this method, it is hard to solve many problems. After all these years, people purposed more and more complicated ideas for improving, many of them use distributed Deep-RL which needs tons of cores to run the simulators. However, the basic ideas behind all this technique are sometimes just a modified DQN. So we asked a simple question, is there a more elegant way to improve the DQN model? Instead of adding more and more small fixes on it, we redesign the problem setting under a popular entropy regularization framework which leads to better performance and theoretical guarantee. Finally, we purposed SQN, a new off-policy algorithm with better performance and stability.