 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Comparisons of CNN with Other Learning Algorithms for Text Classification in Legal Document Review
Paper and Code
Dec 19, 2019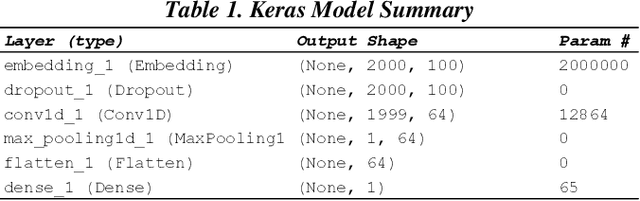
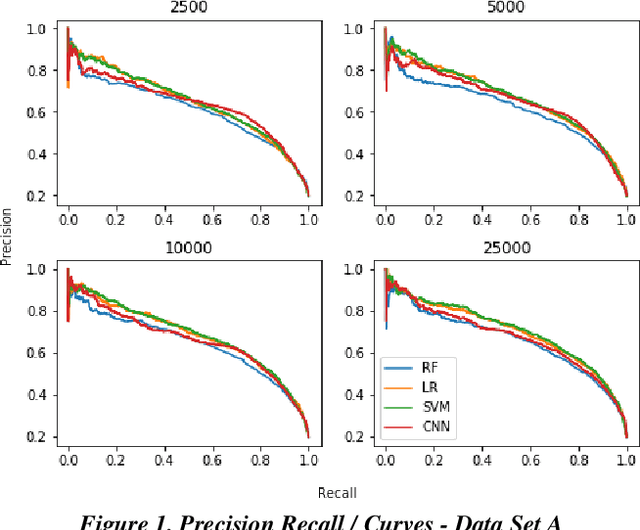
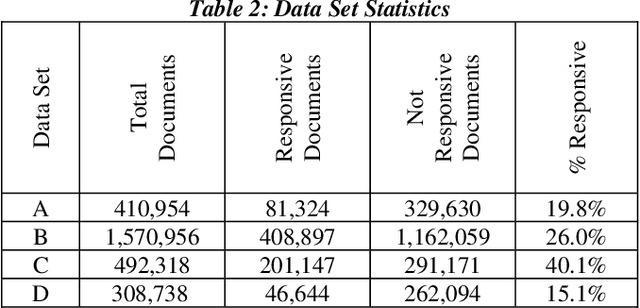
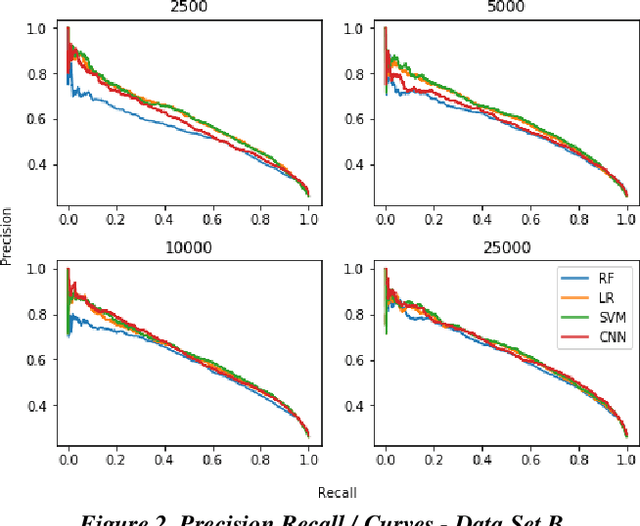
Research has shown that Convolutional Neural Networks (CNN) can be effectively applied to text classification as part of a predictive coding protocol. That said, most research to date has been conducted on data sets with short documents that do not reflect the variety of documents in real world document reviews. Using data from four actual reviews with documents of varying lengths, we compared CNN with other popular machine learning algorithms for text classification, including Logistic Regression, Support Vector Machine, and Random Forest. For each data set, classification models were trained with different training sample sizes using different learning algorithms. These models were then evaluated using a large randomly sampled test set of documents, and the results were compared using precision and recall curves. Our study demonstrates that CNN performed well, but that there was no single algorithm that performed the best across the combination of data sets and training sample sizes. These results will help advance research into the legal profession's use of machine learning algorithms that maximize performance.