 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-wise Depth and Motion Learning from Monocular Videos
Paper and Code
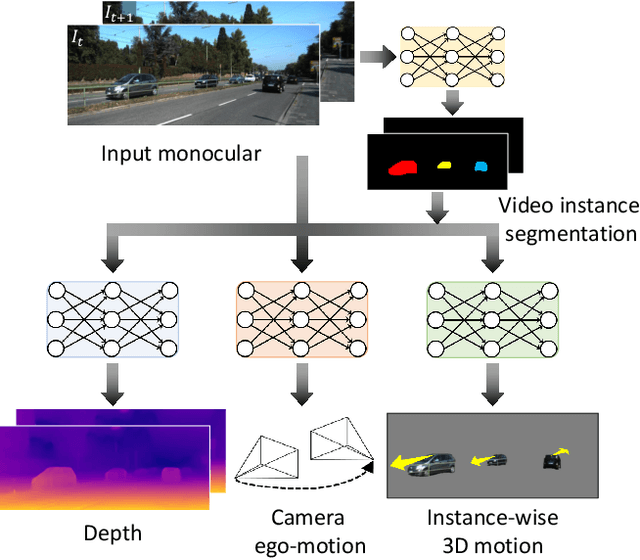
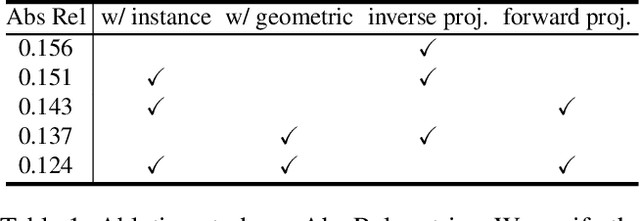
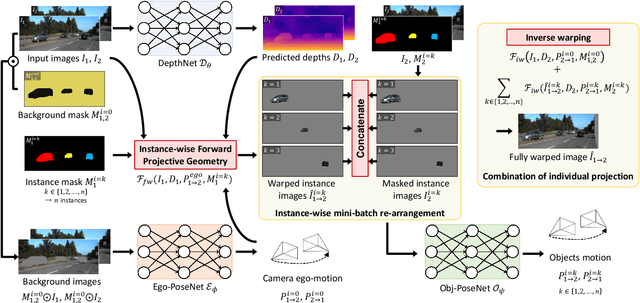
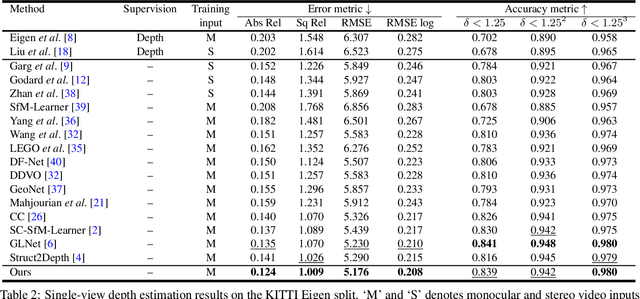
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. The only annotation used in our pipeline is a video instance segmentation map that can be predicted by our new auto-annotation scheme. Our technical contributions are three-fold. First, we propose a differentiable forward rigid projection module that plays a key role in our instance-wise depth and motion learning. Second, we design an instance-wise photometric and geometric consistency loss that effectively decomposes background and moving object regions. Lastly, we introduce an instance-wise mini-batch re-arrangement scheme that does not require additional iterations in training. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods.