 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarginalized State Distribution Entropy Regularization in Policy Optimization
Paper and Code
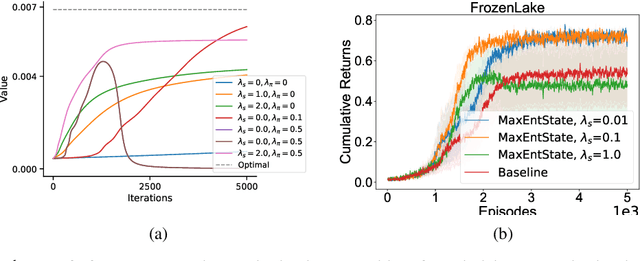
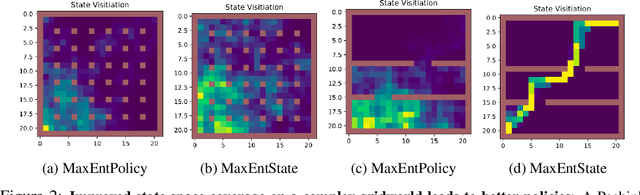
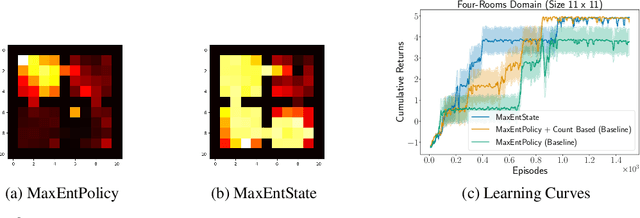
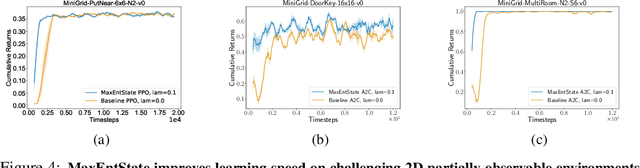
Entropy regularization is used to get improved optimization performance in reinforcement learning tasks. A common form of regularization is to maximize policy entropy to avoid premature convergence and lead to more stochastic policies for exploration through action space. However, this does not ensure exploration in the state space. In this work, we instead consider the distribution of discounted weighting of states, and propose to maximize the entropy of a lower bound approximation to the weighting of a state, based on latent space state representation. We propose entropy regularization based on the marginal state distribution, to encourage the policy to have a more uniform distribution over the state space for exploration. Our approach based on marginal state distribution achieves superior state space coverage on complex gridworld domains, that translate into empirical gains in sparse reward 3D maze navigation and continuous control domains compared to entropy regularization with stochastic policies.