 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeOccNet: Learning to See Through Foreground Occlusions in Light Fields
Paper and Code

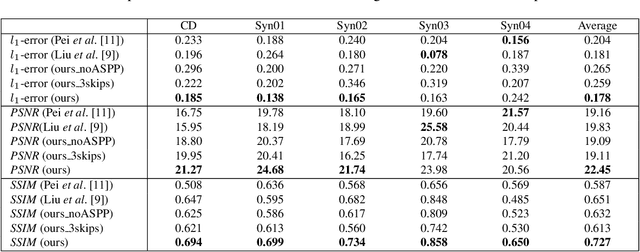
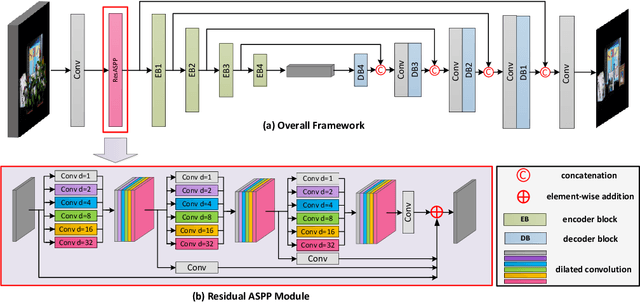
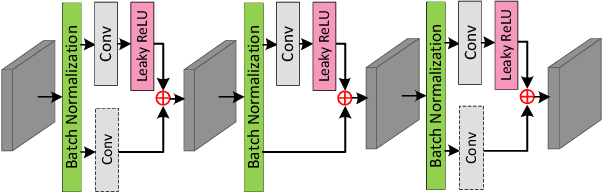
Background objects occluded in some views of a light field (LF) camera can be seen by other views. Consequently, occluded surfaces are possible to be reconstructed from LF images. In this paper, we handle the LF de-occlusion (LF-DeOcc) problem using a deep encoder-decoder network (namely, DeOccNet). In our method, sub-aperture images (SAIs) are first given to the encoder to incorporate both spatial and angular information. The encoded representations are then used by the decoder to render an occlusionfree center-view SAI. To the best of our knowledge, DeOccNet is the first deep learning-based LF-DeOcc method. To handle the insufficiency of training data, we propose an LF synthesis approach to embed selected occlusion masks into existing LF images. Besides, several synthetic and realworld LFs are developed for performance evaluation. Experimental results show that, after training on the generated data, our DeOccNet can effectively remove foreground occlusions and achieves superior performance as compared to other state-of-the-art methods. Source codes are available at: https://github.com/YingqianWang/DeOccNet.