 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynchronous Transformers for End-to-End Speech Recognition
Paper and Code
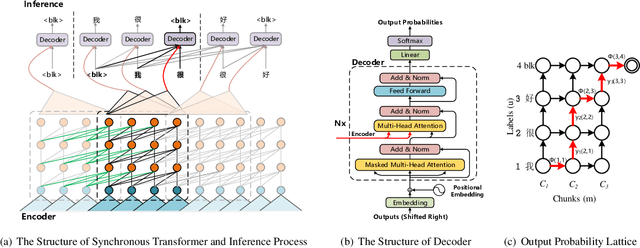
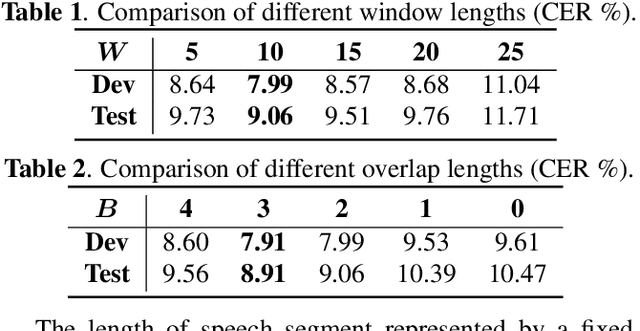

For most of the attention-based sequence-to-sequence models, the decoder predicts the output sequence conditioned on the entire input sequence processed by the encoder. The asynchronous problem between the encoding and decoding makes these models difficult to be applied for online speech recognition. In this paper, we propose a model named synchronous transformer to address this problem, which can predict the output sequence chunk by chunk. Once a fixed-length chunk of the input sequence is processed by the encoder, the decoder begins to predict symbols immediately. During training, a forward-backward algorithm is introduced to optimize all the possible alignment paths. Our model is evaluated on a Mandarin dataset AISHELL-1. The experiments show that the synchronous transformer is able to perform encoding and decoding synchronously, and achieves a character error rate of 8.91% on the test set.