 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Object Tracking and Segmentation from Automatic Annotations
Paper and Code
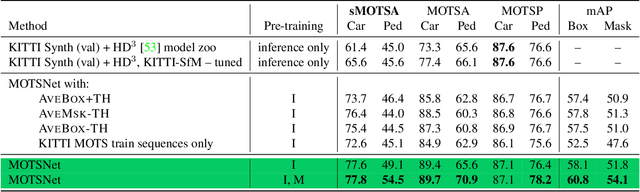
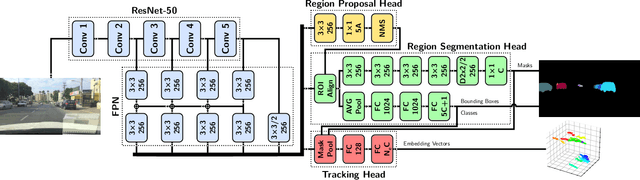
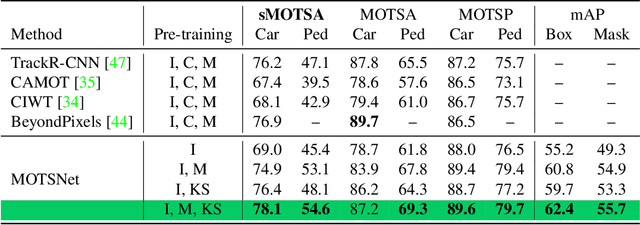
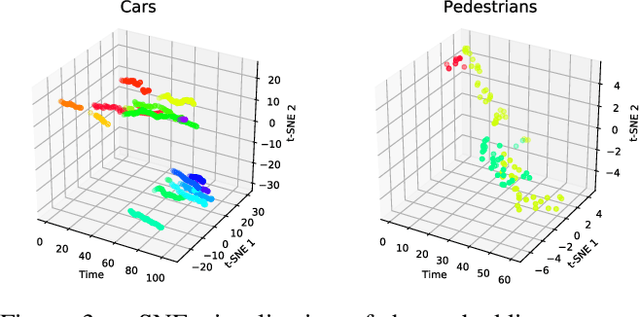
In this work we contribute a novel pipeline to automatically generate training data, and to improve over state-of-the-art multi-object tracking and segmentation (MOTS) methods. Our proposed tracklet mining algorithm turns raw street-level videos into high-fidelity MOTS training data, is scalable and overcomes the need of expensive and time-consuming manual annotation approaches. We leverage state-of-the-art instance segmentation results in combination with optical flow obtained from models also trained on automatically harvested training data. Our second major contribution is MOTSNet - a deep learning, tracking-by-detection architecture for MOTS - deploying a novel mask-pooling layer for improved object association over time. Training MOTSNet with our automatically extracted data leads to significantly improved sMOTSA scores on the novel KITTI MOTS dataset (+1.9%/+7.5% on cars/pedestrians). Even without learning from a single, manually annotated MOTS training example we still improve over prior state-of-the-art, confirming the compelling properties of our pipeline. On the MOTSChallenge dataset we improve by +4.1%, further confirming the efficacy of our proposed MOTSNet.