 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-policy Reinforcement Learning with Entropy Regularization
Paper and Code
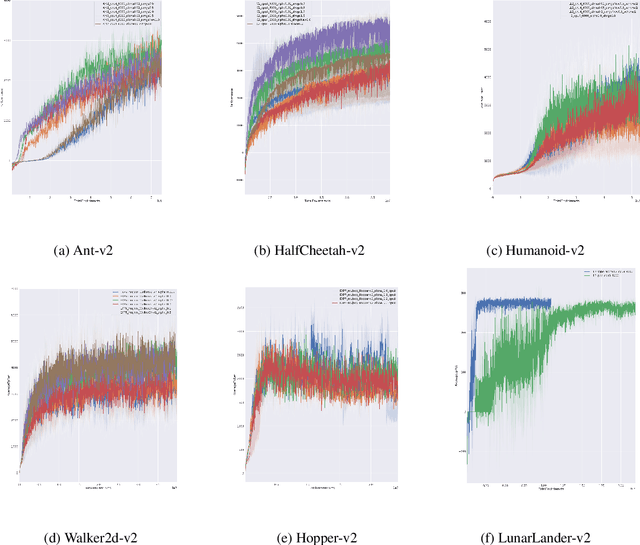
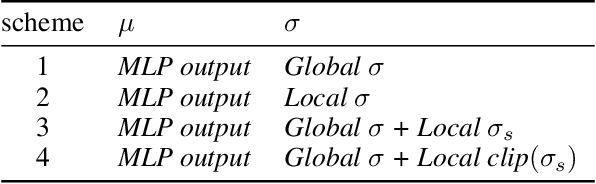
Entropy regularization is an imported idea in reinforcement learning, with great success in recent algorithms like Soft Actor Critic and Soft Q Network. In this work we extend this idea into the on-policy realm. With the soft gradient policy theorem, we construct the maximum entropy reinforcement learning framework for on-policy RL. For policy gradient based on-policy algorithms, policy network is often represented as Gaussian distribution with the action variance restricted to be global for all the states observed from the environment. We propose an idea called action variance scale for policy network and find it can work collaboratively with the idea of entropy regularization. In this paper, we choose the state-of-the-art on-policy algorithm, Proximal Policy Optimization, as our basal algorithm and present Soft Proximal Policy Optimization (SPPO). PPO is a popular on-policy RL algorithm with great stability and parallelism. But like many on-policy algorithm, PPO can also suffer from low sample efficiency and local optimum problem. In the entropy-regularized framework, SPPO can guide the agent to succeed at the task while maintaining exploration by acting as randomly as possible. Our method outperforms prior works on a range of continuous control benchmark tasks, Furthermore, our method can be easily extended to large scale experiment and achieve stable learning at high throughput.