 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Knowledge Within: Methods for Data-Free Model Compression
Paper and Code
Dec 03, 2019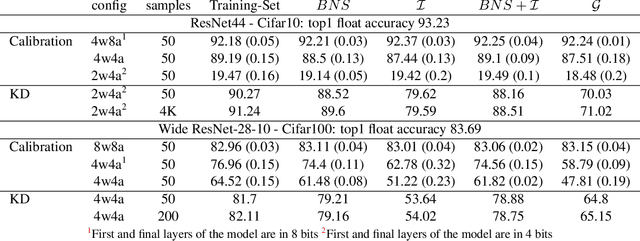
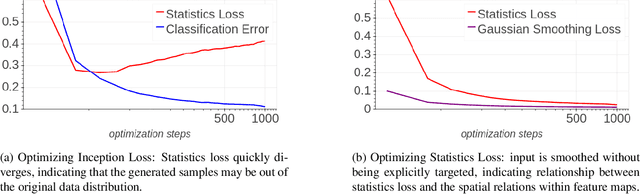
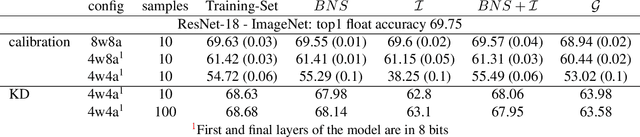
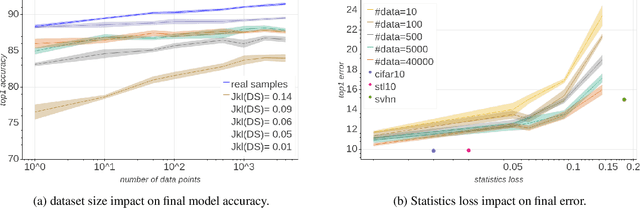
Background: Recently, an extensive amount of research has been focused on compressing and accelerating Deep Neural Networks (DNNs). So far, high compression rate algorithms required the entire training dataset, or its subset, for fine-tuning and low precision calibration process. However, this requirement is unacceptable when sensitive data is involved as in medical and biometric use-cases. Contributions: We present three methods for generating synthetic samples from trained models. Then, we demonstrate how these samples can be used to fine-tune or to calibrate quantized models with negligible accuracy degradation compared to the original training set --- without using any real data in the process. Furthermore, we suggest that our best performing method, leveraging intrinsic batch normalization layers' statistics of a trained model, can be used to evaluate data similarity. Our approach opens a path towards genuine data-free model compression, alleviating the need for training data during deployment.