 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Replay for Real-Time Continual Learning
Paper and Code
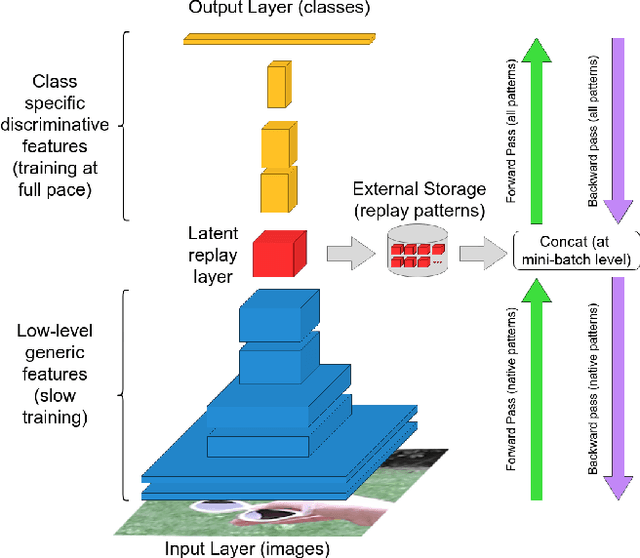
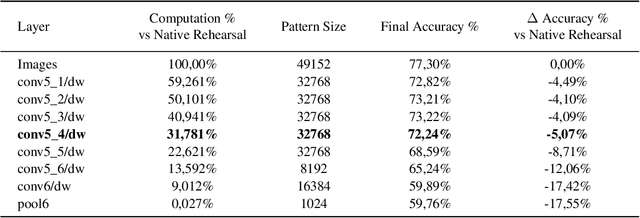
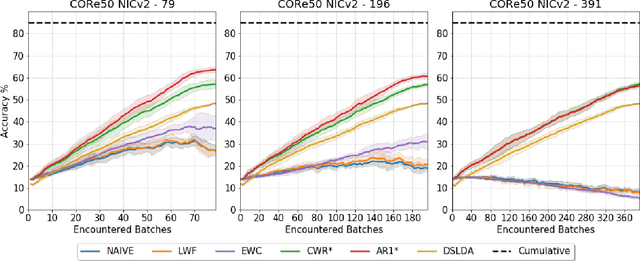
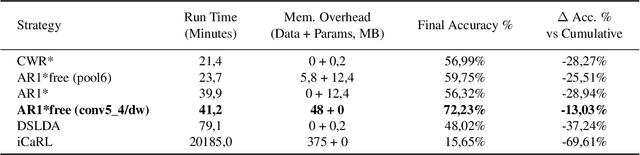
Training deep networks on light computational devices is nowadays very challenging. Continual learning techniques, where complex models are incrementally trained on small batches of new data, can make the learning problem tractable even for CPU-only edge devices. However, a number of practical problems need to be solved: catastrophic forgetting before anything else. In this paper we introduce an original technique named ``Latent Replay'' where, instead of storing a portion of past data in the input space, we store activations volumes at some intermediate layer. This can significantly reduce the computation and storage required by native rehearsal. To keep the representation stable and the stored activations valid we propose to slow-down learning at all the layers below the latent replay one, leaving the layers above free to learn at full pace. In our experiments we show that Latent Replay, combined with existing continual learning techniques, achieves state-of-the-art accuracy on a difficult benchmark such as CORe50 NICv2 with nearly 400 small and highly non-i.i.d. batches. Finally, we demonstrate the feasibility of nearly real-time continual learning on the edge through the porting of the proposed technique on a smartphone device.