 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Classifying Sepsis Heterogeneity in the ICU: Insight Using Machine Learning
Paper and Code
Dec 03, 2019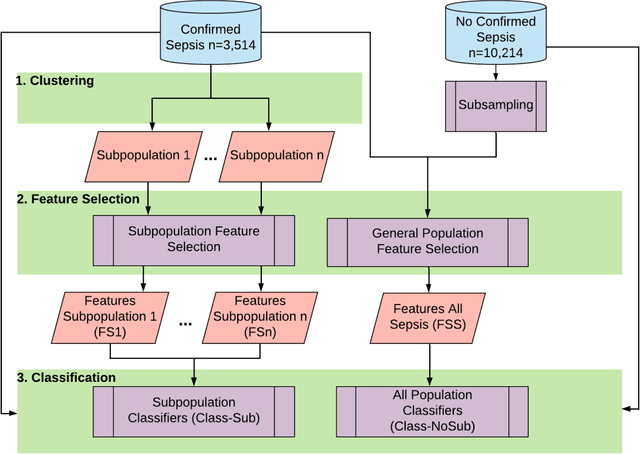
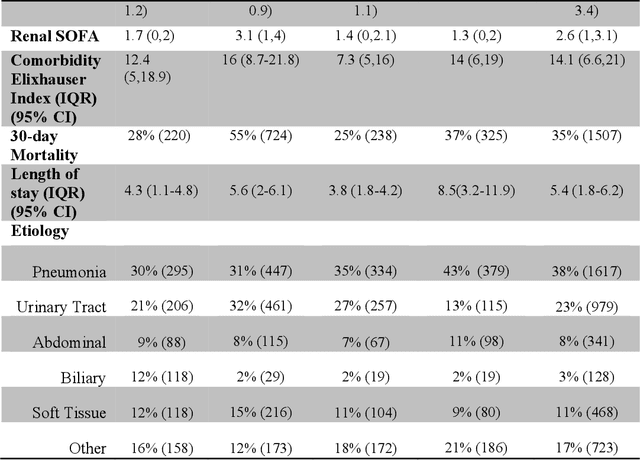
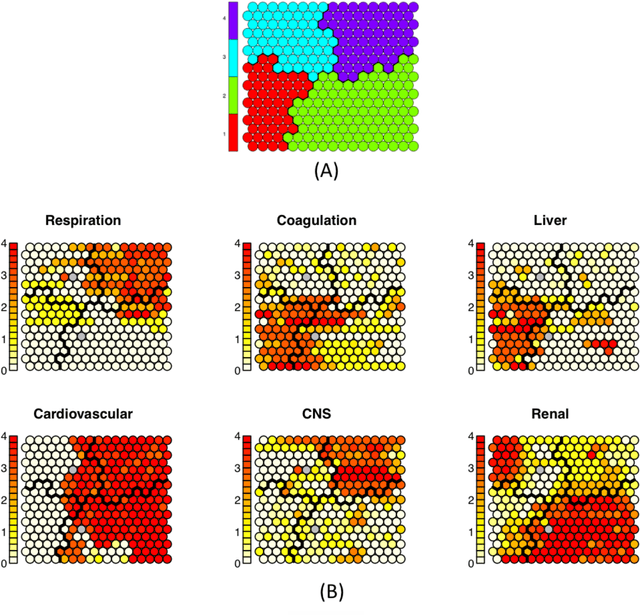
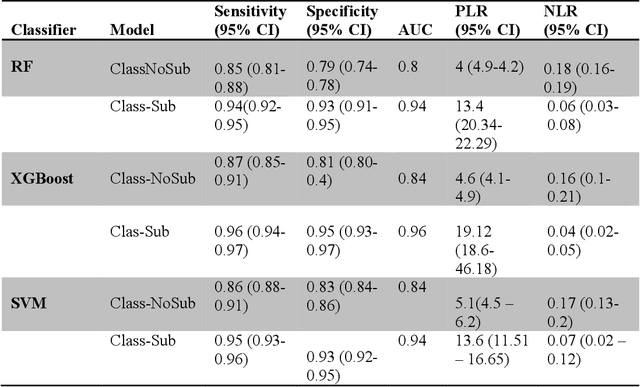
Current machine learning models aiming to predict sepsis from Electronic Health Records (EHR) do not account for the heterogeneity of the condition, despite its emerging importance in prognosis and treatment. This work demonstrates the added value of stratifying the types of organ dysfunction observed in patients who develop sepsis in the ICU in improving the ability to recognise patients at risk of sepsis from their EHR data. Using an ICU dataset of 13,728 records, we identify clinically significant sepsis subpopulations with distinct organ dysfunction patterns. Classification experiments using Random Forest, Gradient Boost Trees and Support Vector Machines, aiming to distinguish patients who develop sepsis in the ICU from those who do not, show that features selected using sepsis subpopulations as background knowledge yield a superior performance regardless of the classification model used. Our findings can steer machine learning efforts towards more personalised models for complex conditions including sepsis.