 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIABLE: Fast Adaptation via Backpropagating Learned Loss
Paper and Code
Nov 29, 2019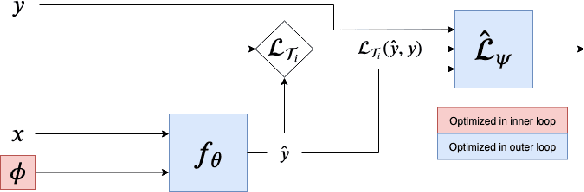
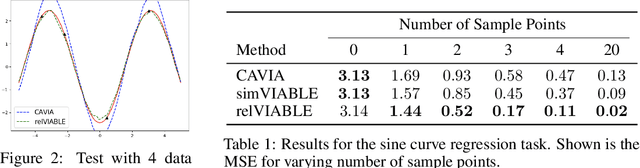
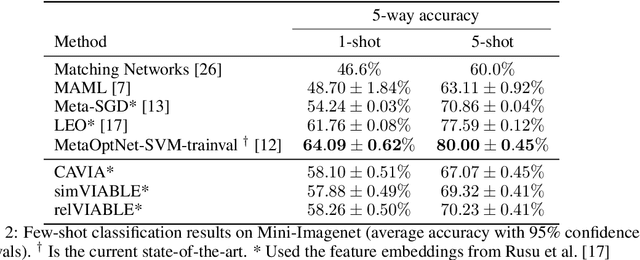
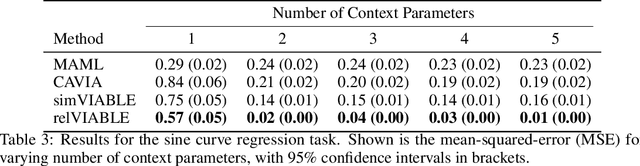
In few-shot learning, typically, the loss function which is applied at test time is the one we are ultimately interested in minimising, such as the mean-squared-error loss for a regression problem. However, given that we have few samples at test time, we argue that the loss function that we are interested in minimising is not necessarily the loss function most suitable for computing gradients in a few-shot setting. We propose VIABLE, a generic meta-learning extension that builds on existing meta-gradient-based methods by learning a differentiable loss function, replacing the pre-defined inner-loop loss function in performing task-specific updates. We show that learning a loss function capable of leveraging relational information between samples reduces underfitting, and significantly improves performance and sample efficiency on a simple regression task. Furthermore, we show VIABLE is scalable by evaluating on the Mini-Imagenet dataset.