 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Structure Extraction for Forms using Very High Resolution Semantic Segmentation
Paper and Code
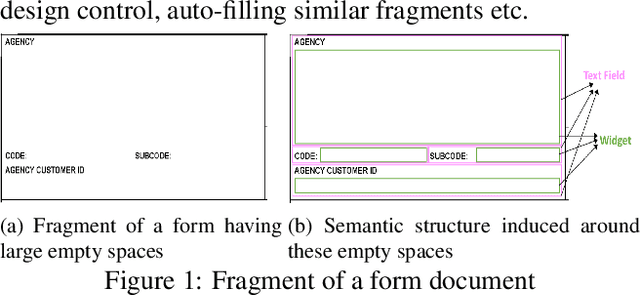
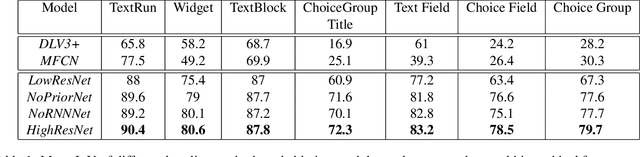

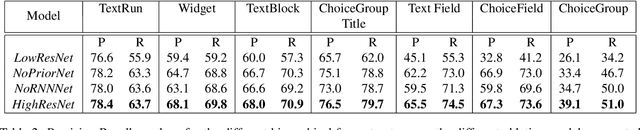
In this work, we look at the problem of structure extraction from document images with a specific focus on forms. Forms as a document class have not received much attention, even though they comprise a significant fraction of documents and enable several applications. Forms possess a rich, complex, hierarchical, and high-density semantic structure that poses several challenges to semantic segmentation methods. We propose a prior based deep CNN-RNN hierarchical network architecture that enables document structure extraction using very high resolution(1800 x 1000) images. We divide the document image into overlapping horizontal strips such that the network segments a strip and uses its prediction mask as prior while predicting the segmentation for the subsequent strip. We perform experiments establishing the effectiveness of our strip based network architecture through ablation methods and comparison with low-resolution variations. We introduce our new rich human-annotated forms dataset, and we show that our method significantly outperforms other segmentation baselines in extracting several hierarchical structures on this dataset. We also outperform other baselines in table detection task on the Marmot dataset. Our method is currently being used in a world-leading customer experience management software suite for automated conversion of paper and PDF forms to modern HTML based forms.