 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Bi-Fusion Feature Pyramid Network for Accurate Single-shot Object Detection
Paper and Code
Dec 10, 2019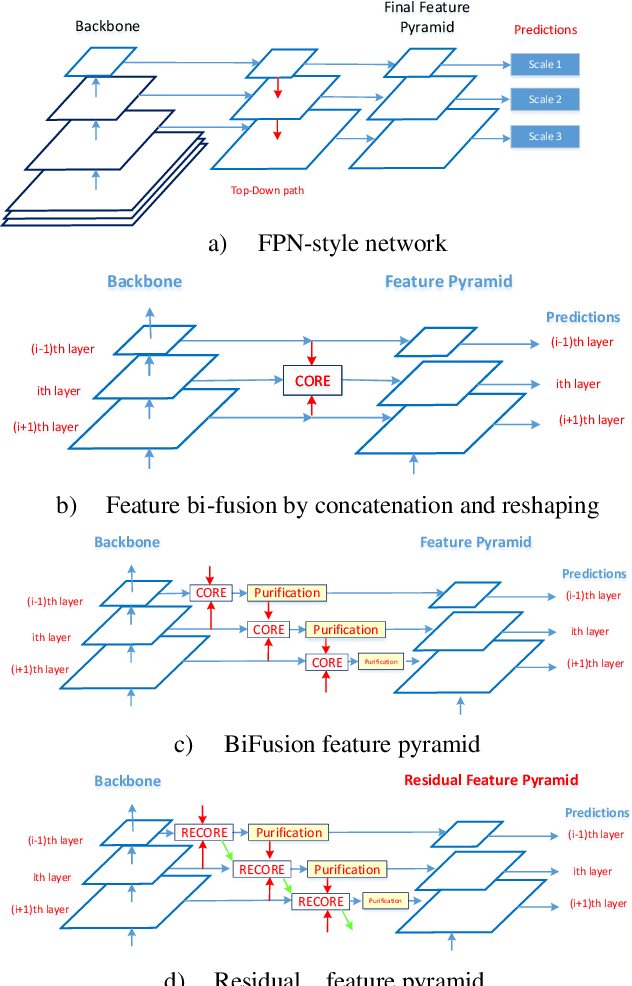
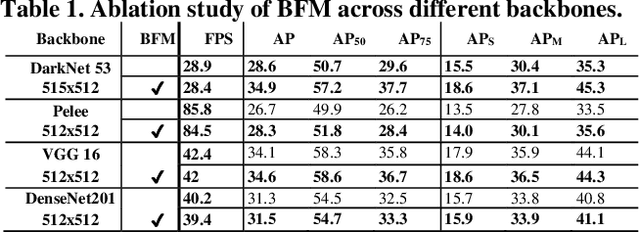
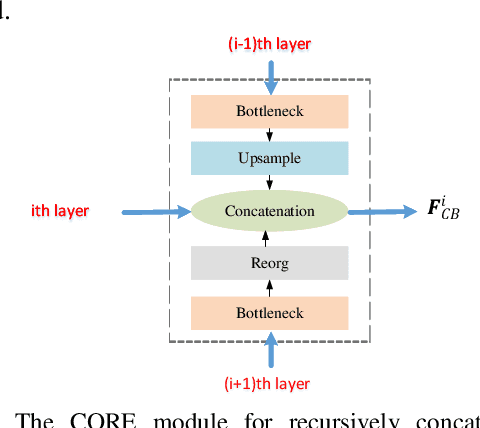
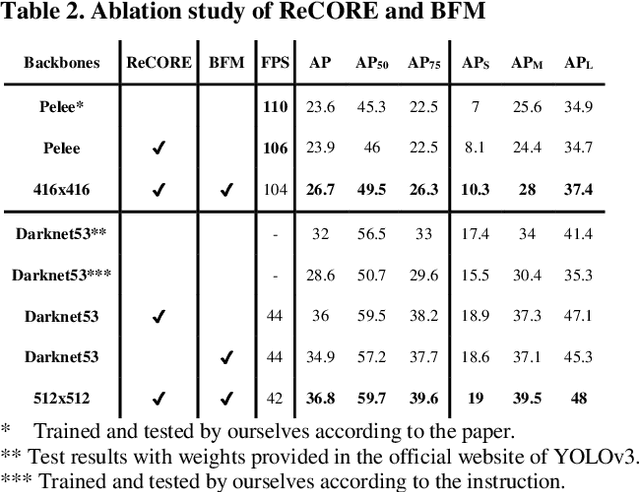
State-of-the-art (SoTA) models have improved the accuracy of object detection with a large margin via a FP (feature pyramid). FP is a top-down aggregation to collect semantically strong features to improve scale invariance in both two-stage and one-stage detectors. However, this top-down pathway cannot preserve accurate object positions due to the shift-effect of pooling. Thus, the advantage of FP to improve detection accuracy will disappear when more layers are used. The original FP lacks a bottom-up pathway to offset the lost information from lower-layer feature maps. It performs well in large-sized object detection but poor in small-sized object detection. A new structure "residual feature pyramid" is proposed in this paper. It is bidirectional to fuse both deep and shallow features towards more effective and robust detection for both small-sized and large-sized objects. Due to the "residual" nature, it can be easily trained and integrated to different backbones (even deeper or lighter) than other bi-directional methods. One important property of this residual FP is: accuracy improvement is still found even if more layers are adopted. Extensive experiments on VOC and MS COCO datasets showed the proposed method achieved the SoTA results for highly-accurate and efficient object detection..