 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Certificates for Sparse Adversarial Attacks by Randomized Ablation
Paper and Code

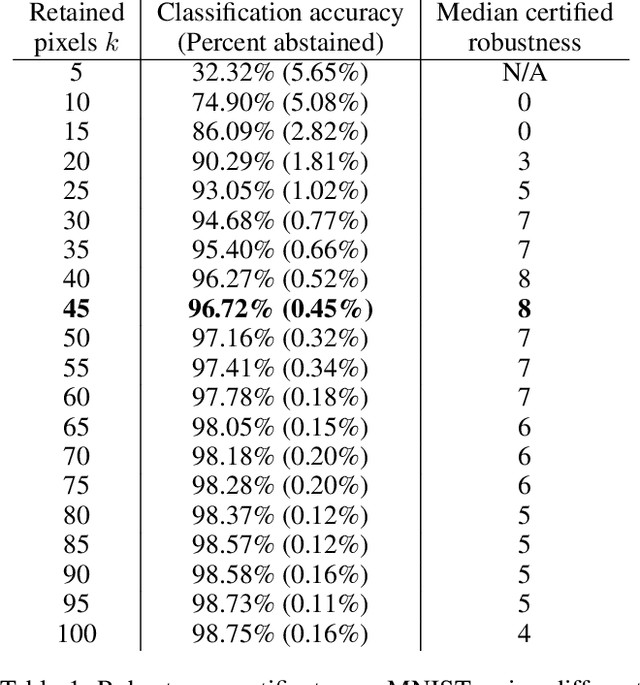
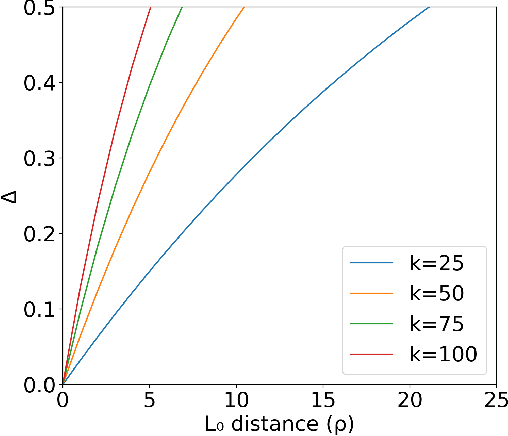
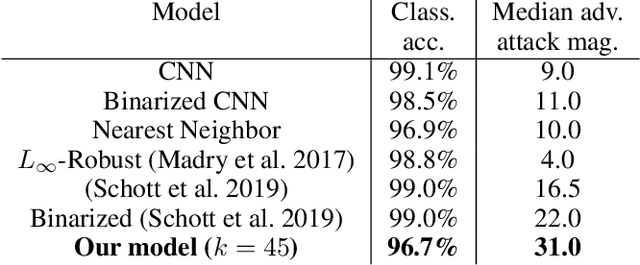
Recently, techniques have been developed to provably guarantee the robustness of a classifier to adversarial perturbations of bounded L_1 and L_2 magnitudes by using randomized smoothing: the robust classification is a consensus of base classifications on randomly noised samples where the noise is additive. In this paper, we extend this technique to the L_0 threat model. We propose an efficient and certifiably robust defense against sparse adversarial attacks by randomly ablating input features, rather than using additive noise. Experimentally, on MNIST, we can certify the classifications of over 50% of images to be robust to any distortion of at most 8 pixels. This is comparable to the observed empirical robustness of unprotected classifiers on MNIST to modern L_0 attacks, demonstrating the tightness of the proposed robustness certificate. We also evaluate our certificate on ImageNet and CIFAR-10. Our certificates represent an improvement on those provided in a concurrent work (Lee et al. 2019) which uses random noise rather than ablation (median certificates of 8 pixels versus 4 pixels on MNIST; 16 pixels versus 1 pixel on ImageNet.) Additionally, we empirically demonstrate that our classifier is highly robust to modern sparse adversarial attacks on MNIST. Our classifications are robust, in median, to adversarial perturbations of up to 31 pixels, compared to 22 pixels reported as the state-of-the-art defense, at the cost of a slight decrease (around 2.3%) in the classification accuracy. Code is available at https://github.com/alevine0/randomizedAblation/.