 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Top-k Sparsification in Distributed Deep Learning
Paper and Code
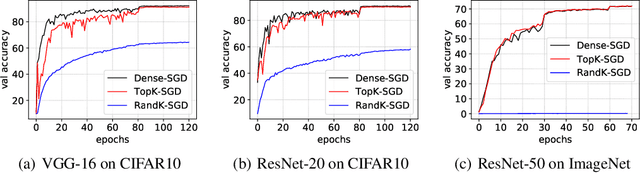
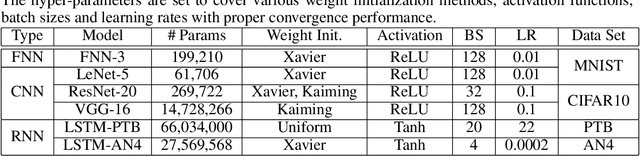
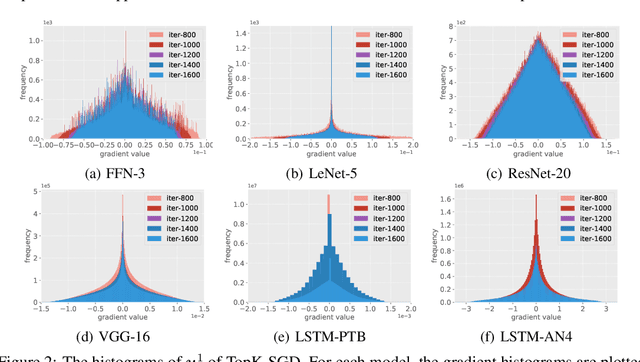
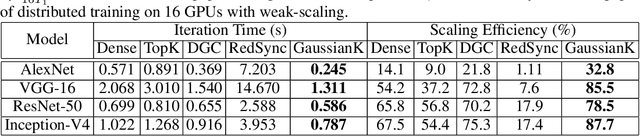
Distributed stochastic gradient descent (SGD) algorithms are widely deployed in training large-scale deep learning models, while the communication overhead among workers becomes the new system bottleneck. Recently proposed gradient sparsification techniques, especially Top-$k$ sparsification with error compensation (TopK-SGD), can significantly reduce the communication traffic without an obvious impact on the model accuracy. Some theoretical studies have been carried out to analyze the convergence property of TopK-SGD. However, existing studies do not dive into the details of Top-$k$ operator in gradient sparsification and use relaxed bounds (e.g., exact bound of Random-$k$) for analysis; hence the derived results cannot well describe the real convergence performance of TopK-SGD. To this end, we first study the gradient distributions of TopK-SGD during the training process through extensive experiments. We then theoretically derive a tighter bound for the Top-$k$ operator. Finally, we exploit the property of gradient distribution to propose an approximate top-$k$ selection algorithm, which is computing-efficient for GPUs, to improve the scaling efficiency of TopK-SGD by significantly reducing the computing overhead. Codes are available at: \url{https://github.com/hclhkbu/GaussianK-SGD}.