 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison as a Cure: Detecting & Neutralizing Variable-Sized Backdoor Attacks in Deep Neural Networks
Paper and Code

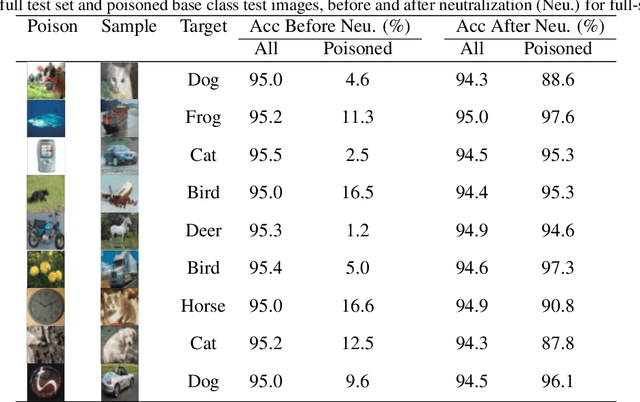
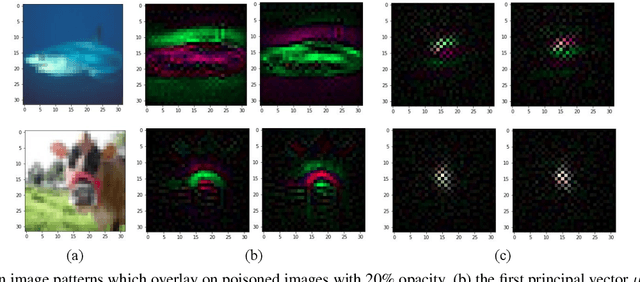
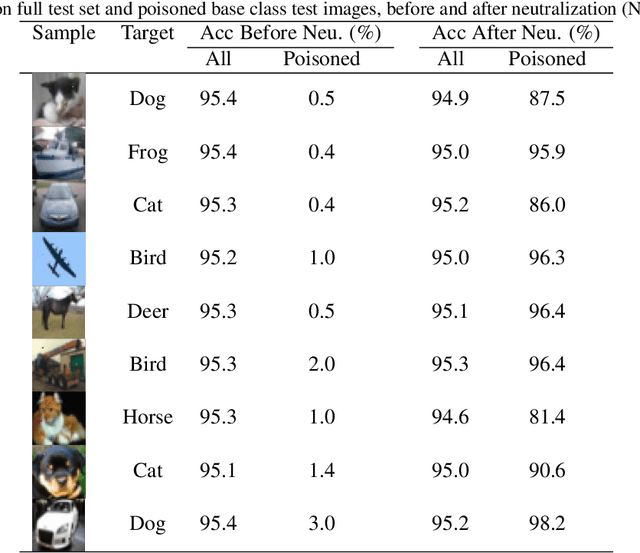
Deep learning models have recently shown to be vulnerable to backdoor poisoning, an insidious attack where the victim model predicts clean images correctly but classifies the same images as the target class when a trigger poison pattern is added. This poison pattern can be embedded in the training dataset by the adversary. Existing defenses are effective under certain conditions such as a small size of the poison pattern, knowledge about the ratio of poisoned training samples or when a validated clean dataset is available. Since a defender may not have such prior knowledge or resources, we propose a defense against backdoor poisoning that is effective even when those prerequisites are not met. It is made up of several parts: one to extract a backdoor poison signal, detect poison target and base classes, and filter out poisoned from clean samples with proven guarantees. The final part of our defense involves retraining the poisoned model on a dataset augmented with the extracted poison signal and corrective relabeling of poisoned samples to neutralize the backdoor. Our approach has shown to be effective in defending against backdoor attacks that use both small and large-sized poison patterns on nine different target-base class pairs from the CIFAR10 dataset.