 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Vision for Improved Human-Robot Cooperation in Adverse Underwater Conditions
Paper and Code

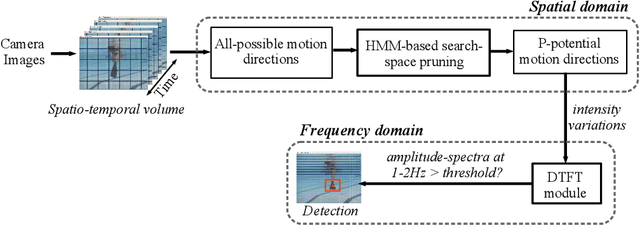
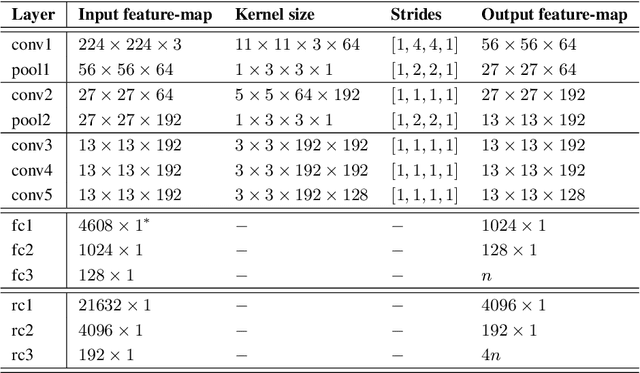
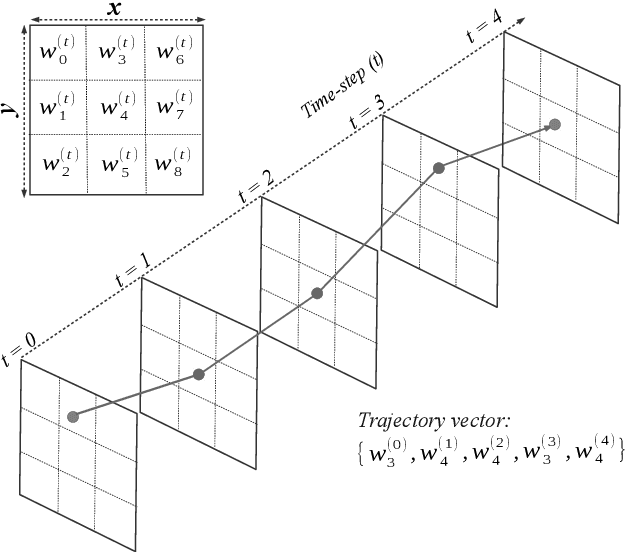
Visually-guided underwater robots are widely used in numerous autonomous exploration and surveillance applications alongside humans for cooperative task execution. However, underwater visual perception is challenging due to marine artifacts such as poor visibility, lighting variation, scattering, etc. Additionally, chromatic distortions and scarcity of salient visual features make it harder for an underwater robot to visually interpret its surroundings to effectively assist its companion diver during an underwater mission. In this paper, we delineate our attempts to address these challenges by designing novel and improved vision-based solutions. Specifically, we present robust methodologies for autonomous diver following, human-robot communication, automatic image enhancement, and image super-resolution. We depict their algorithmic details and describe relevant design choices to meet the real-time operating constraints on single-board embedded machines. Moreover, through extensive simulation and field experiments, we demonstrate how an autonomous robot can exploit these solutions to understand human motion and hand gesture-based instructions even in adverse visual conditions. As an immediate next step, we want to focus on relative pose estimation and visual attention modeling of an underwater robot based on its companion humans' body-pose and temporal activity recognition. We believe that these autonomous capabilities will facilitate a faster and better interpretation of visual scenes and enable more effective underwater human-robot cooperation.