 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Massive Collection of Cross-Lingual Web-Document Pairs
Paper and Code
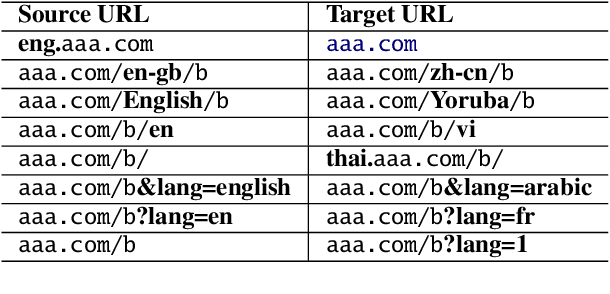

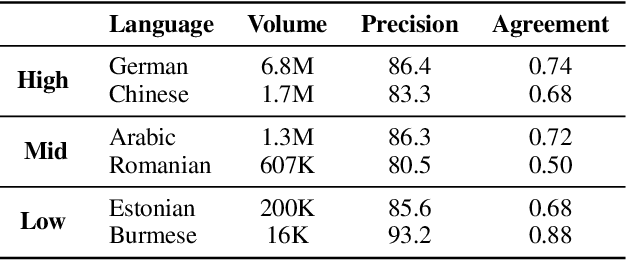

Cross-lingual document alignment aims to identify pairs of documents in two distinct languages that are of comparable content or translations of each other. Small-scale efforts have been made to collect aligned document level data on a limited set of language-pairs such as English-German or on limited comparable collections such as Wikipedia. In this paper, we mine twelve snapshots of the Common Crawl corpus and identify web document pairs that are translations of each other. We release a new web dataset consisting of 54 million URL pairs from Common Crawl covering documents in 92 languages paired with English. We evaluate the quality of the dataset by measuring the quality of machine translations from models that have been trained on mined parallel sentence pairs from this aligned corpora and introduce a simple yet effective baseline for identifying these aligned documents. The objective of this dataset and paper is to foster new research in cross-lingual NLP across a variety of low, mid, and high-resource languages.