 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edget-SS3: a text classifier with dynamic n-grams for early risk detection over text streams
Paper and Code
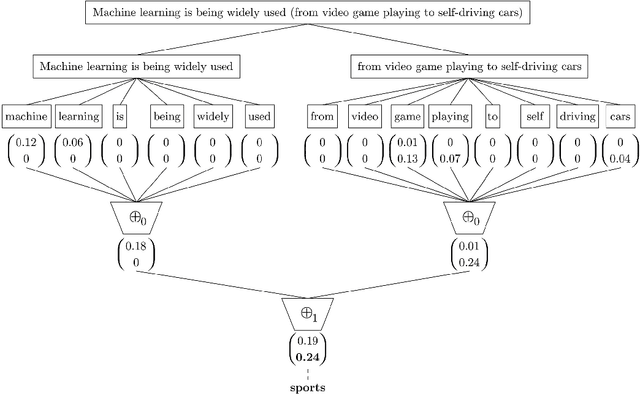
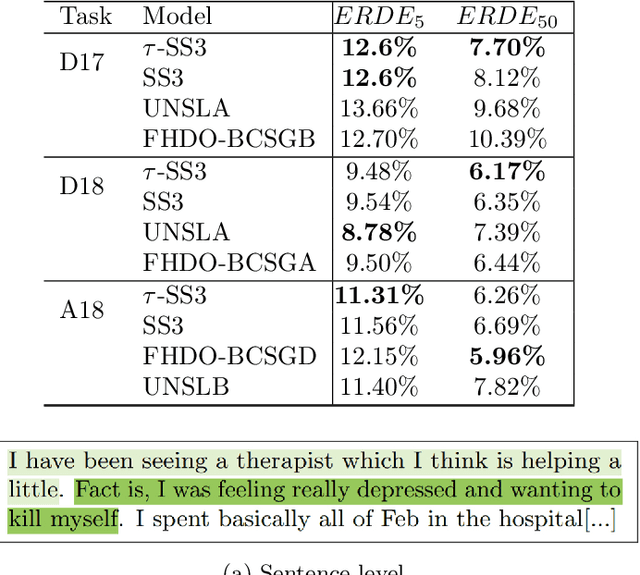
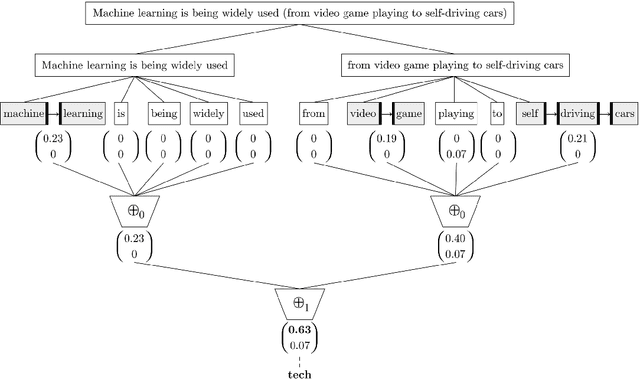
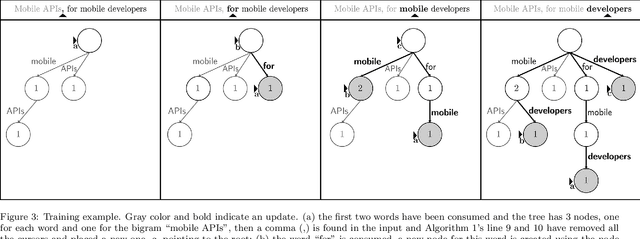
A recently introduced classifier, called SS3, has shown to be well suited to deal with early risk detection (ERD) problems on text streams. It obtained state-of-the-art performance on early depression and anorexia detection on Reddit in the CLEF's eRisk open tasks. SS3 was created to naturally deal with ERD problems since: it supports incremental training and classification over text streams and it can visually explain its rationale. However, SS3 processes the input using a bag-of-word model lacking the ability to recognize important word sequences. This could negatively affect the classification performance and also reduces the descriptiveness of visual explanations. In the standard document classification field, it is very common to use word n-grams to try to overcome some of these limitations. Unfortunately, when working with text streams, using n-grams is not trivial since the system must learn and recognize which n-grams are important ``on the fly''. This paper introduces t-SS3, a variation of SS3 which expands the model to dynamically recognize useful patterns over text streams. We evaluated our model on the eRisk 2017 and 2018 tasks on early depression and anorexia detection. Experimental results show that t-SS3 is able to improve both, existing results and the richness of visual explanations.