 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Few-Shot Learn Across Diverse Natural Language Classification Tasks
Paper and Code
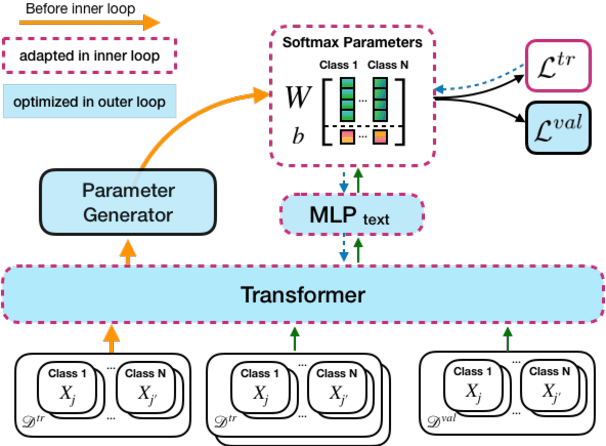
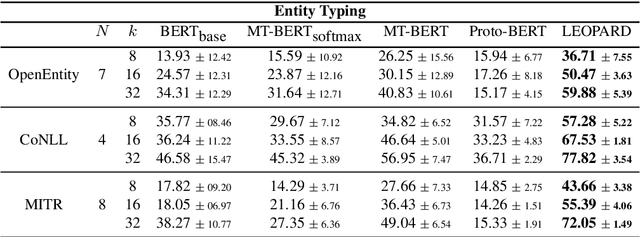

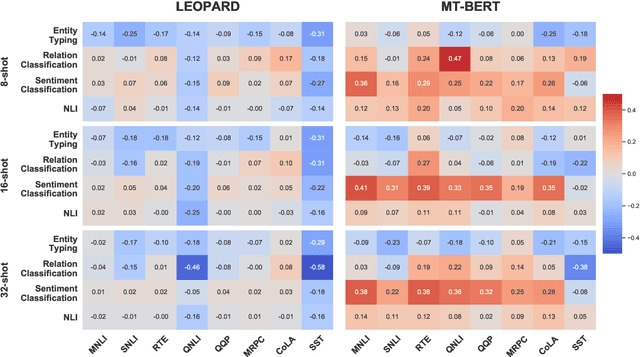
Self-supervised pre-training of transformer models has shown enormous success in improving performance on a number of downstream tasks. However, fine-tuning on a new task still requires large amounts of task-specific labelled data to achieve good performance. We consider this problem of learning to generalize to new tasks with few examples as a meta-learning problem. While meta-learning has shown tremendous progress in recent years, its application is still limited to simulated problems or problems with limited diversity across tasks. We develop a novel method, LEOPARD, which enables optimization-based meta-learning across tasks with different number of classes, and evaluate existing methods on generalization to diverse NLP classification tasks. LEOPARD is trained with the state-of-the-art transformer architecture and shows strong generalization to tasks not seen at all during training, with as few as 8 examples per label. On 16 NLP datasets, across a diverse task-set such as entity typing, relation extraction, natural language inference, sentiment analysis, and several other text categorization tasks, we show that LEOPARD learns better initial parameters for few-shot learning than self-supervised pre-training or multi-task training, outperforming many strong baselines, for example, increasing F1 from 49% to 72%.