 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Requirement Reduction of Deep Neural Networks Using Low-bit Quantization of Parameters
Paper and Code
Nov 01, 2019

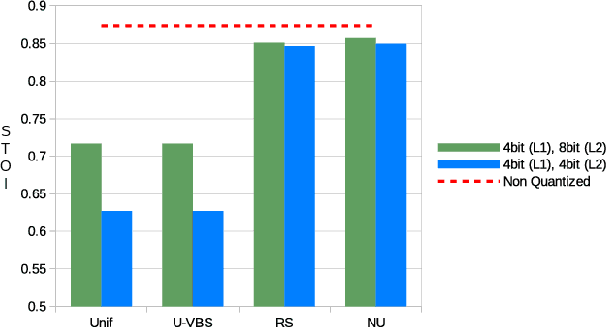
Effective employment of deep neural networks (DNNs) in mobile devices and embedded systems is hampered by requirements for memory and computational power. This paper presents a non-uniform quantization approach which allows for dynamic quantization of DNN parameters for different layers and within the same layer. A virtual bit shift (VBS) scheme is also proposed to improve the accuracy of the proposed scheme. Our method reduces the memory requirements, preserving the performance of the network. The performance of our method is validated in a speech enhancement application, where a fully connected DNN is used to predict the clean speech spectrum from the input noisy speech spectrum. A DNN is optimized and its memory footprint and performance are evaluated using the short-time objective intelligibility, STOI, metric. The application of the low-bit quantization allows a 50% reduction of the DNN memory footprint while the STOI performance drops only by 2.7%.