 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank HOCA: Efficient High-Order Cross-Modal Attention for Video Captioning
Paper and Code
Nov 01, 2019
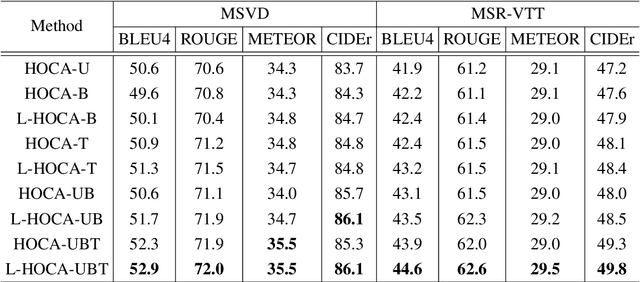
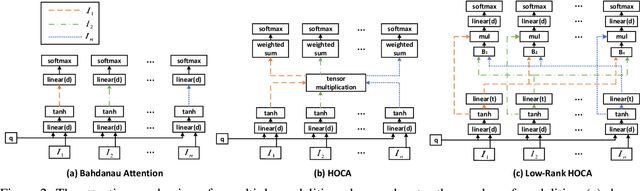
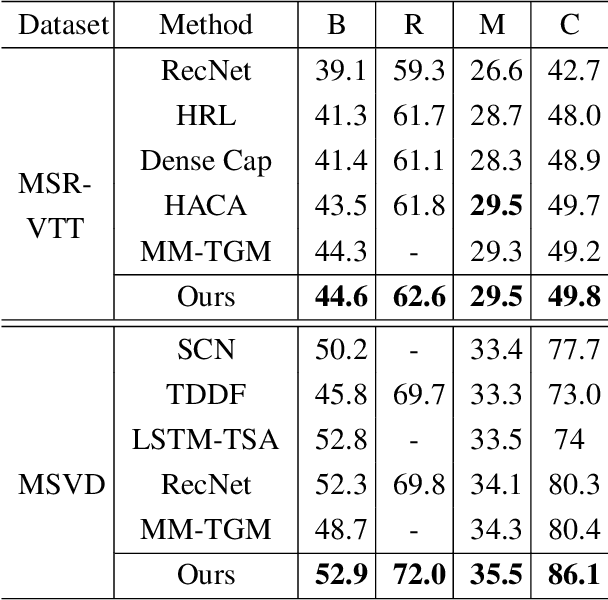
This paper addresses the challenging task of video captioning which aims to generate descriptions for video data. Recently, the attention-based encoder-decoder structures have been widely used in video captioning. In existing literature, the attention weights are often built from the information of an individual modality, while, the association relationships between multiple modalities are neglected. Motivated by this observation, we propose a video captioning model with High-Order Cross-Modal Attention (HOCA) where the attention weights are calculated based on the high-order correlation tensor to capture the frame-level cross-modal interaction of different modalities sufficiently. Furthermore, we novelly introduce Low-Rank HOCA which adopts tensor decomposition to reduce the extremely large space requirement of HOCA, leading to a practical and efficient implementation in real-world applications. Experimental results on two benchmark datasets, MSVD and MSR-VTT, show that Low-rank HOCA establishes a new state-of-the-art.