 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self Validation Network for Object-Level Human Attention Estimation
Paper and Code

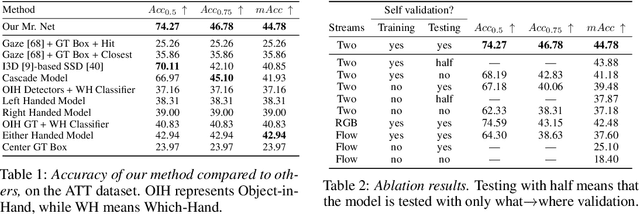
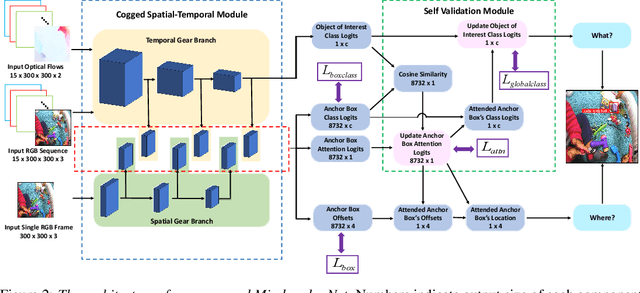

Due to the foveated nature of the human vision system, people can focus their visual attention on a small region of their visual field at a time, which usually contains only a single object. Estimating this object of attention in first-person (egocentric) videos is useful for many human-centered real-world applications such as augmented reality applications and driver assistance systems. A straightforward solution for this problem is to pick the object whose bounding box is hit by the gaze, where eye gaze point estimation is obtained from a traditional eye gaze estimator and object candidates are generated from an off-the-shelf object detector. However, such an approach can fail because it addresses the where and the what problems separately, despite that they are highly related, chicken-and-egg problems. In this paper, we propose a novel unified model that incorporates both spatial and temporal evidence in identifying as well as locating the attended object in firstperson videos. It introduces a novel Self Validation Module that enforces and leverages consistency of the where and the what concepts. We evaluate on two public datasets, demonstrating that Self Validation Module significantly benefits both training and testing and that our model outperforms the state-of-the-art.