 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG2G: TTS-Driven Pronunciation Learning for Graphemic Hybrid ASR
Paper and Code
Oct 22, 2019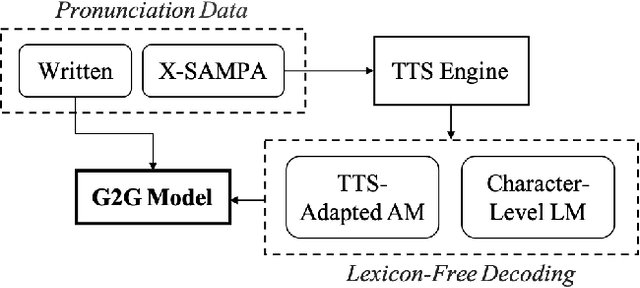
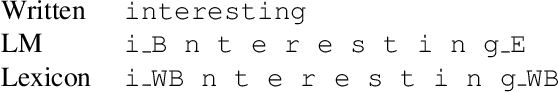
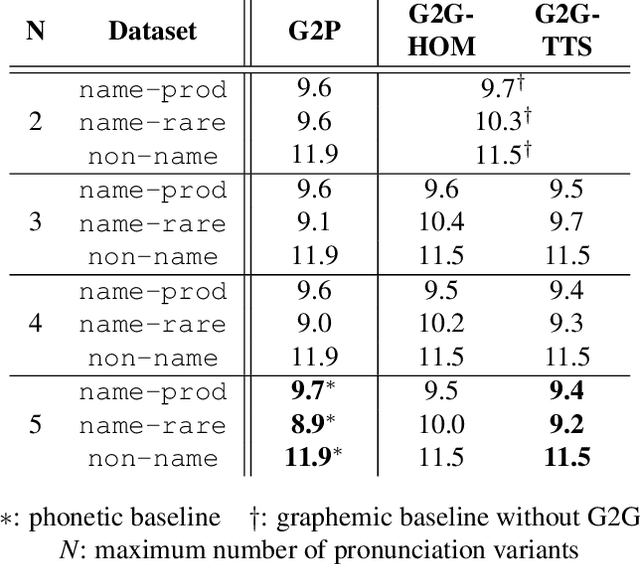
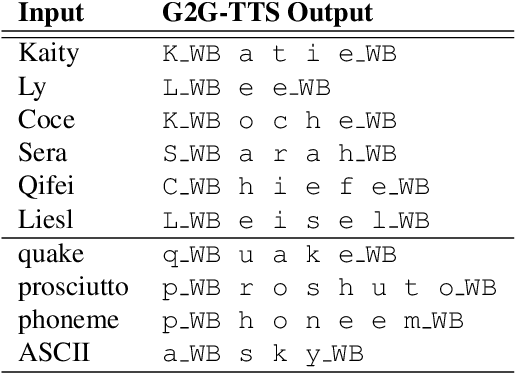
Grapheme-based acoustic modeling has recently been shown to outperform phoneme-based approaches in both hybrid and end-to-end automatic speech recognition (ASR), even on non-phonemic languages like English. However, graphemic ASR still has problems with rare long-tail words that do not follow the standard spelling conventions seen in training, such as entity names. In this work, we present a novel method to train a statistical grapheme-to-grapheme (G2G) model on text-to-speech data that can rewrite an arbitrary character sequence into more phonetically consistent forms. We show that using G2G to provide alternative pronunciations during decoding reduces Word Error Rate by 3% to 11% relative over a strong graphemic baseline and bridges the gap on rare name recognition with an equivalent phonetic setup. Unlike many previously proposed methods, our method does not require any change to the acoustic model training procedure. This work reaffirms the efficacy of grapheme-based modeling and shows that specialized linguistic knowledge, when available, can be leveraged to improve graphemic ASR.