 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Track Any Object
Paper and Code
Oct 25, 2019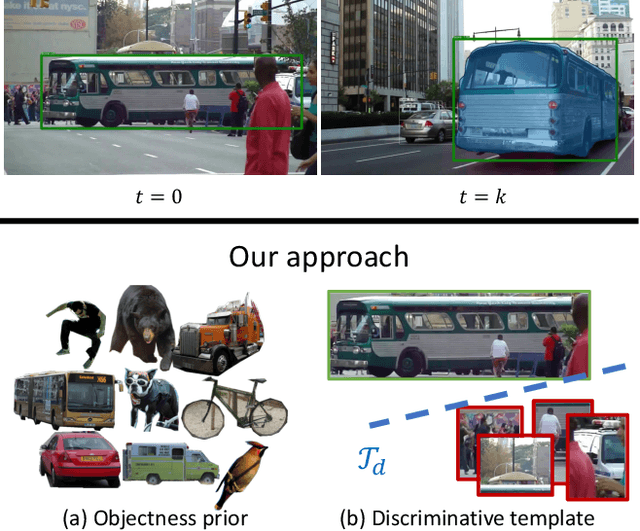
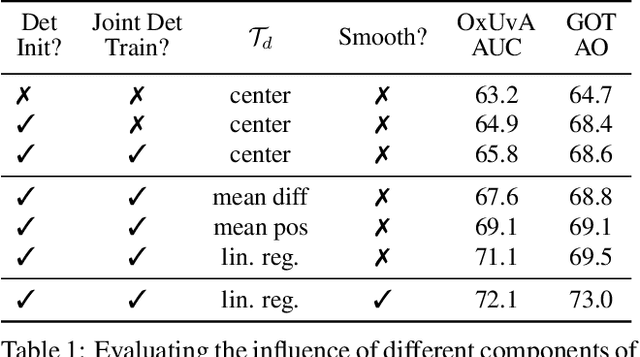
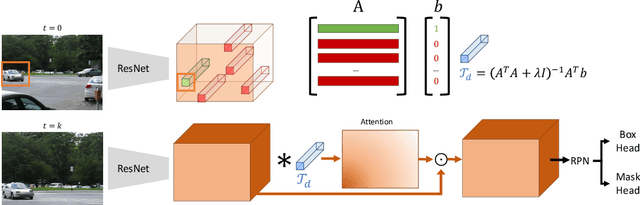
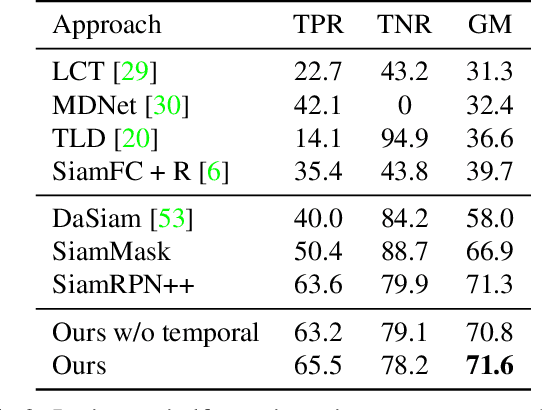
Object tracking can be formulated as "finding the right object in a video". We observe that recent approaches for class-agnostic tracking tend to focus on the "finding" part, but largely overlook the "object" part of the task, essentially doing a template matching over a frame in a sliding-window. In contrast, class-specific trackers heavily rely on object priors in the form of category-specific object detectors. In this work, we re-purpose category-specific appearance models into a generic objectness prior. Our approach converts a category-specific object detector into a category-agnostic, object-specific detector (i.e. a tracker) efficiently, on the fly. Moreover, at test time the same network can be applied to detection and tracking, resulting in a unified approach for the two tasks. We achieve state-of-the-art results on two recent large-scale tracking benchmarks (OxUvA and GOT, using external data). By simply adding a mask prediction branch, our approach is able to produce instance segmentation masks for the tracked object. Despite only using box-level information on the first frame, our method outputs high-quality masks, as evaluated on the DAVIS '17 video object segmentation benchmark.