 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel adversarial training for speaker verification and diarization
Paper and Code
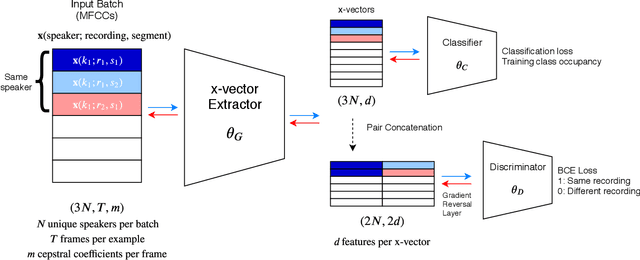
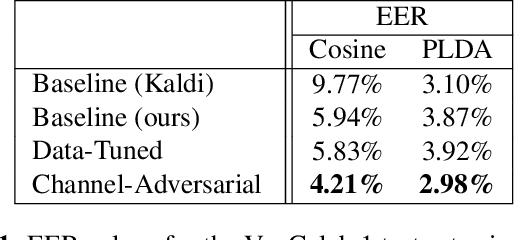
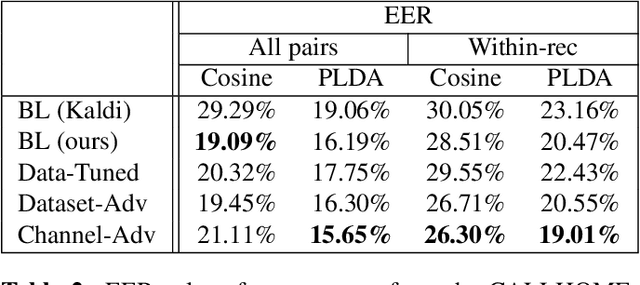
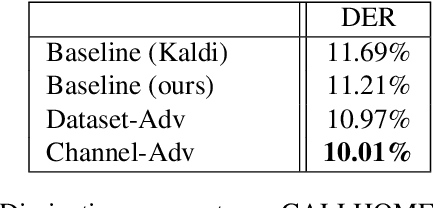
Previous work has encouraged domain-invariance in deep speaker embedding by adversarially classifying the dataset or labelled environment to which the generated features belong. We propose a training strategy which aims to produce features that are invariant at the granularity of the recording or channel, a finer grained objective than dataset- or environment-invariance. By training an adversary to predict whether pairs of same-speaker embeddings belong to the same recording in a Siamese fashion, learned features are discouraged from utilizing channel information that may be speaker discriminative during training. Experiments for verification on VoxCeleb and diarization and verification on CALLHOME show promising improvements over a strong baseline in addition to outperforming a dataset-adversarial model. The VoxCeleb model in particular performs well, achieving a $4\%$ relative improvement in EER over a Kaldi baseline, while using a similar architecture and less training data.