 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling the Output Length of Neural Machine Translation
Paper and Code
Oct 25, 2019

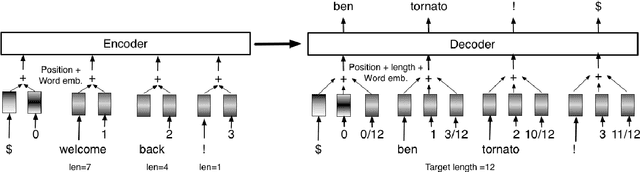
The recent advances introduced by neural machine translation (NMT) are rapidly expanding the application fields of machine translation, as well as reshaping the quality level to be targeted. In particular, if translations have to fit some given layout, quality should not only be measured in terms of adequacy and fluency, but also length. Exemplary cases are the translation of document files, subtitles, and scripts for dubbing, where the output length should ideally be as close as possible to the length of the input text. This paper addresses for the first time, to the best of our knowledge, the problem of controlling the output length in NMT. We investigate two methods for biasing the output length with a transformer architecture: i) conditioning the output to a given target-source length-ratio class and ii) enriching the transformer positional embedding with length information. Our experiments show that both methods can induce the network to generate shorter translations, as well as acquiring interpretable linguistic skills.