 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClotho: An Audio Captioning Dataset
Paper and Code
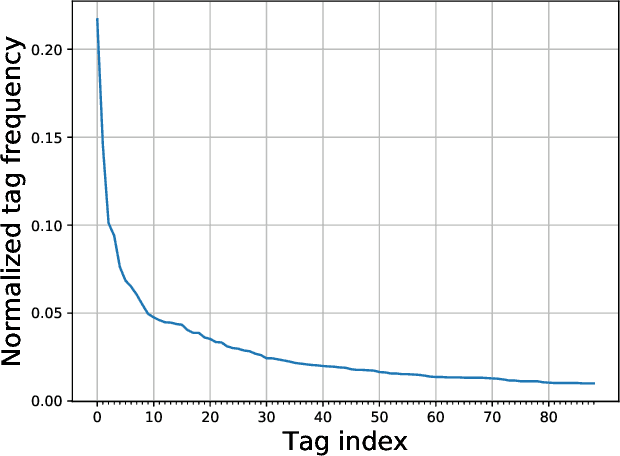
Audio captioning is the novel task of general audio content description using free text. It is an intermodal translation task (not speech-to-text), where a system accepts as an input an audio signal and outputs the textual description (i.e. the caption) of that signal. In this paper we present Clotho, a dataset for audio captioning consisting of 4981 audio samples of 15 to 30 seconds duration and 24 905 captions of eight to 20 words length, and a baseline method to provide initial results. Clotho is built with focus on audio content and caption diversity, and the splits of the data are not hampering the training or evaluation of methods. All sounds are from the Freesound platform, and captions are crowdsourced using Amazon Mechanical Turk and annotators from English speaking countries. Unique words, named entities, and speech transcription are removed with post-processing. Clotho is freely available online (https://zenodo.org/record/3490684).