 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning for Discovering Phonemic Tone Contours
Paper and Code
Oct 20, 2019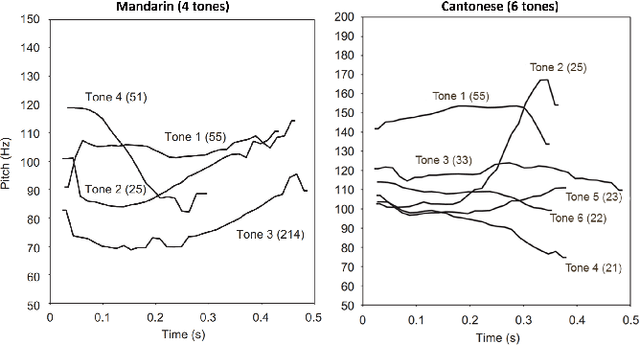
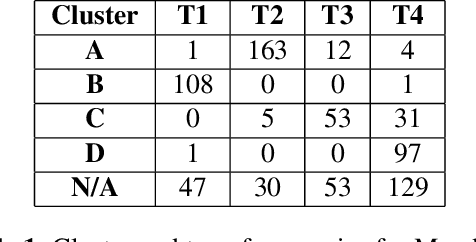
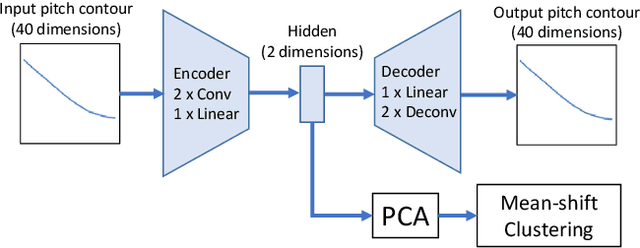
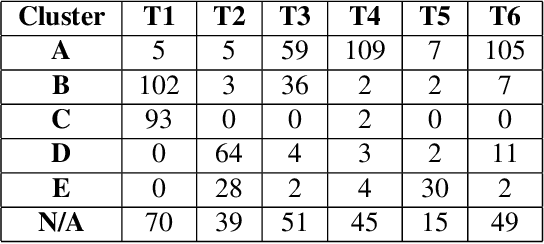
Tone is a prosodic feature used to distinguish words in many languages, some of which are endangered and scarcely documented. In this work, we use unsupervised representation learning to identify probable clusters of syllables that share the same phonemic tone. Our method extracts the pitch for each syllable, then trains a convolutional autoencoder to learn a low dimensional representation for each contour. We then apply the mean shift algorithm to cluster tones in high-density regions of the latent space. Furthermore, by feeding the centers of each cluster into the decoder, we produce a prototypical contour that represents each cluster. We apply this method to spoken multi-syllable words in Mandarin Chinese and Cantonese and evaluate how closely our clusters match the ground truth tone categories. Finally, we discuss some difficulties with our approach, including contextual tone variation and allophony effects.