 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse (group) learning with Lipschitz loss functions: a unified analysis
Paper and Code
Nov 15, 2019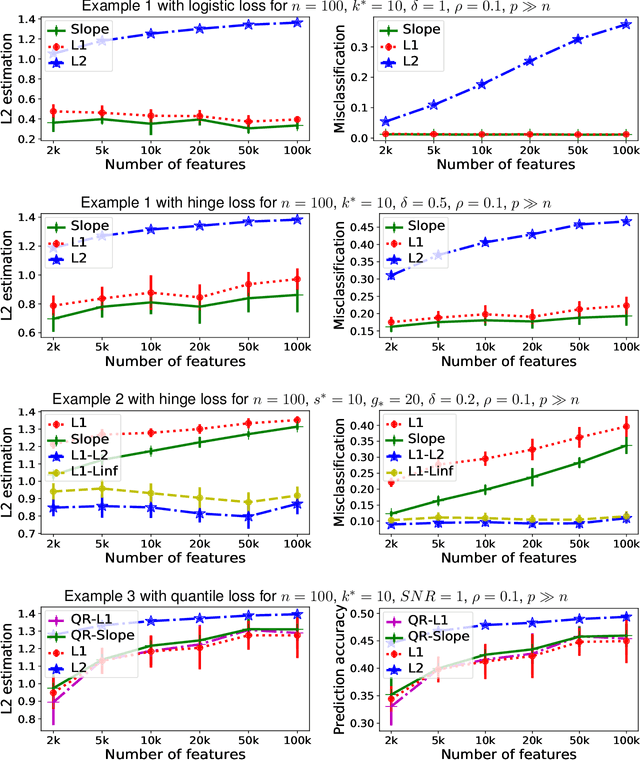
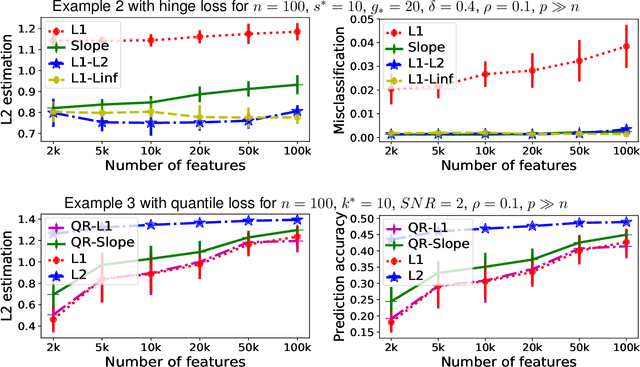
We study a family of sparse estimators defined as minimizers of some empirical Lipschitz loss function---which include hinge, logistic and quantile regression losses---with a convex, sparse or group-sparse regularization. In particular, we consider the L1-norm on the coefficients, its sorted Slope version, and the Group L1-L2 extension. First, we propose a theoretical framework which simultaneously derives new L2 estimation upper bounds for all three regularization schemes. For L1 and Slope regularizations, our bounds scale as $(k^*/n) \log(p/k^*)$---$n\times p$ is the size of the design matrix and $k^*$ the dimension of the theoretical loss minimizer $\beta^*$---matching the optimal minimax rate achieved for the least-squares case. For Group L1-L2 regularization, our bounds scale as $(s^*/n) \log\left( G / s^* \right) + m^* / n$---$G$ is the total number of groups and $m^*$ the number of coefficients in the $s^*$ groups which contain $\beta^*$---and improve over the least-squares case. We additionally show that when the signal is strongly group-sparse Group L1-L2 is superior to L1 and Slope. Our bounds are achieved both in probability and in expectation, under common assumptions in the literature. Second, we propose an accelerated proximal algorithm which computes the convex estimators studied when the number of variables is of the order of $100,000$. We additionally compare their statistical performance of our estimators against standard baselines for settings where the signal is either sparse or group-sparse. Our experiments findings reveal (i) the good empirical performance of L1 and Slope regularizations for sparse binary classification problems, (ii) the superiority of Group L1-L2 regularization for group-sparse classification problems and (iii) the appealing properties of sparse quantile regression estimators for sparse regression problems with heteroscedastic noise.