 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning with Advantage-Based Auxiliary Rewards
Paper and Code
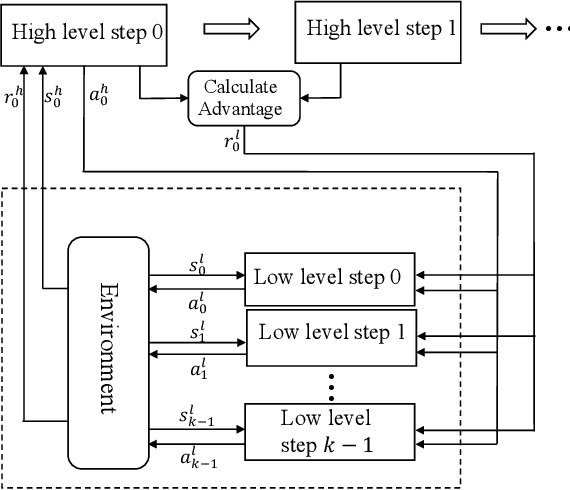
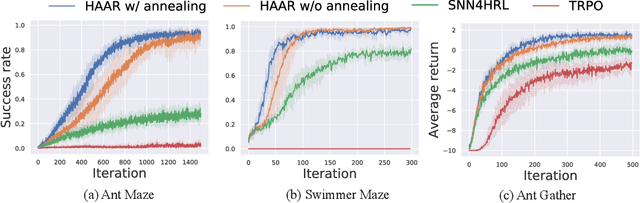

Hierarchical Reinforcement Learning (HRL) is a promising approach to solving long-horizon problems with sparse and delayed rewards. Many existing HRL algorithms either use pre-trained low-level skills that are unadaptable, or require domain-specific information to define low-level rewards. In this paper, we aim to adapt low-level skills to downstream tasks while maintaining the generality of reward design. We propose an HRL framework which sets auxiliary rewards for low-level skill training based on the advantage function of the high-level policy. This auxiliary reward enables efficient, simultaneous learning of the high-level policy and low-level skills without using task-specific knowledge. In addition, we also theoretically prove that optimizing low-level skills with this auxiliary reward will increase the task return for the joint policy. Experimental results show that our algorithm dramatically outperforms other state-of-the-art HRL methods in Mujoco domains. We also find both low-level and high-level policies trained by our algorithm transferable.