 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed filtered hyperinterpolation for noisy data on the sphere
Paper and Code
Oct 06, 2019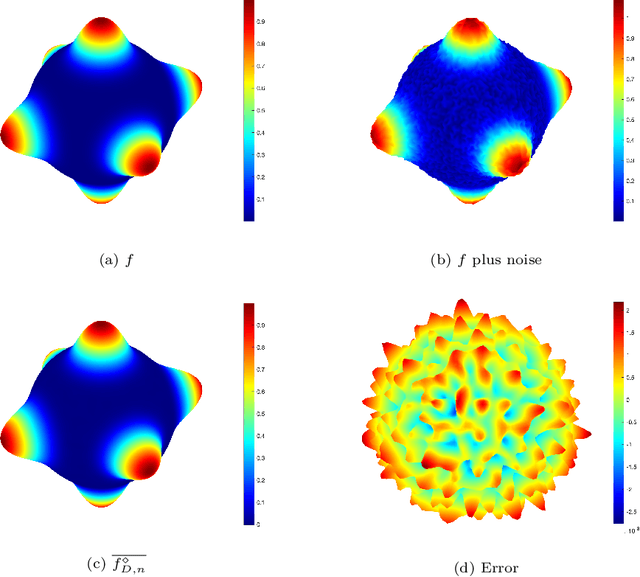
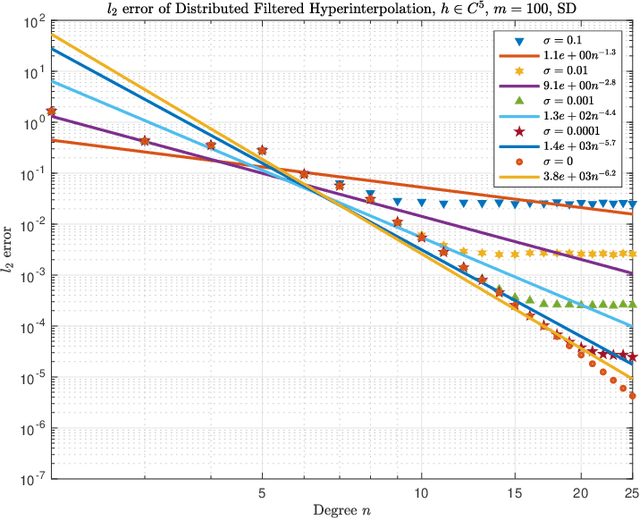
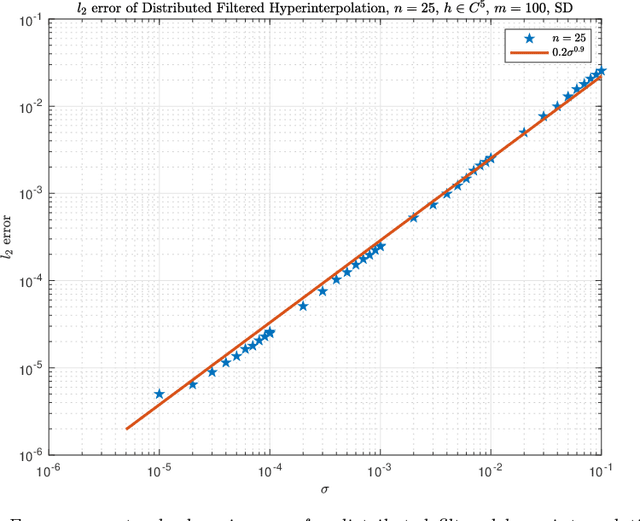
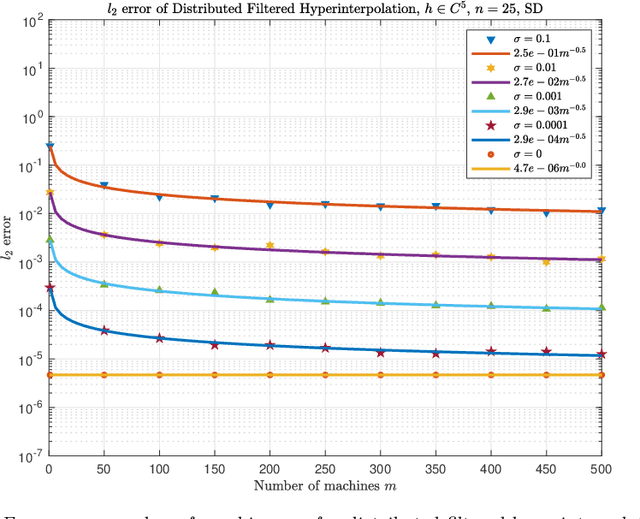
Problems in astrophysics, space weather research and geophysics usually need to analyze noisy big data on the sphere. This paper develops distributed filtered hyperinterpolation for noisy data on the sphere, which assigns the data fitting task to multiple servers to find a good approximation of the mapping of input and output data. For each server, the approximation is a filtered hyperinterpolation on the sphere by a small proportion of quadrature nodes. The distributed strategy allows parallel computing for data processing and model selection and thus reduces computational cost for each server while preserves the approximation capability compared to the filtered hyperinterpolation. We prove quantitative relation between the approximation capability of distributed filtered hyperinterpolation and the numbers of input data and servers. Numerical examples show the efficiency and accuracy of the proposed method.