Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Off-Policy Reinforcement Learning with Conservative Policy Gradients
Paper and Code
Oct 02, 2019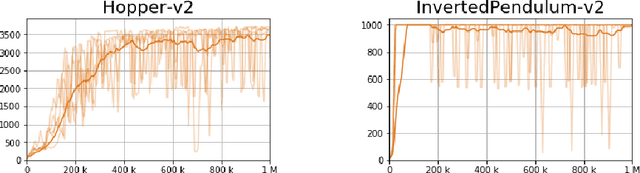

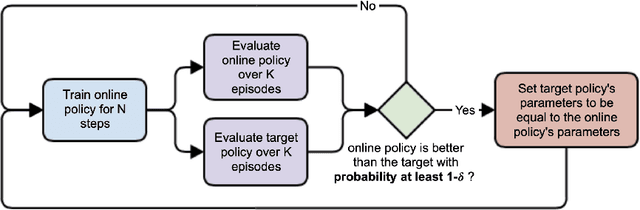
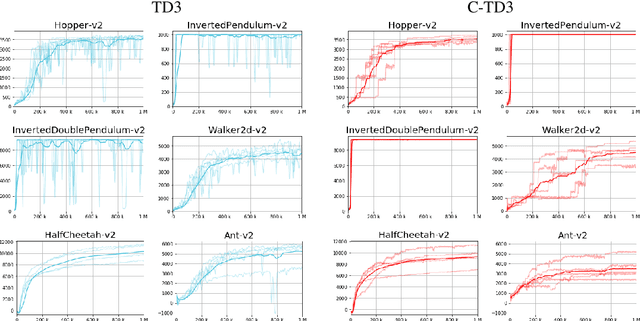
In recent years, advances in deep learning have enabled the application of reinforcement learning algorithms in complex domains. However, they lack the theoretical guarantees which are present in the tabular setting and suffer from many stability and reproducibility problems \citep{henderson2018deep}. In this work, we suggest a simple approach for improving stability and providing probabilistic performance guarantees in off-policy actor-critic deep reinforcement learning regimes. Experiments on continuous action spaces, in the MuJoCo control suite, show that our proposed method reduces the variance of the process and improves the overall performance.
* Under review at ICLR 2020
View paper on
 OpenReview
OpenReview