 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Penalty: Towards Generalization Beyond the IID Assumption
Paper and Code
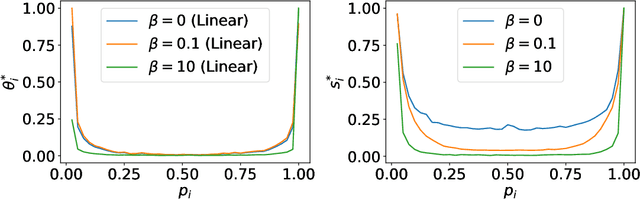
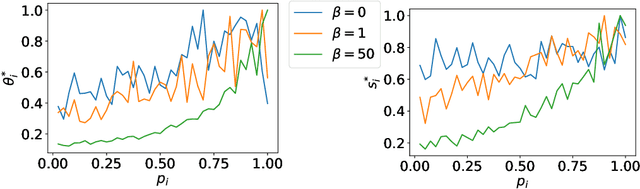
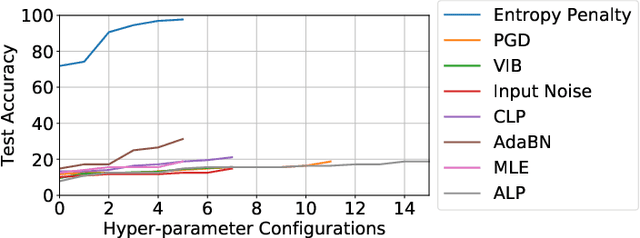
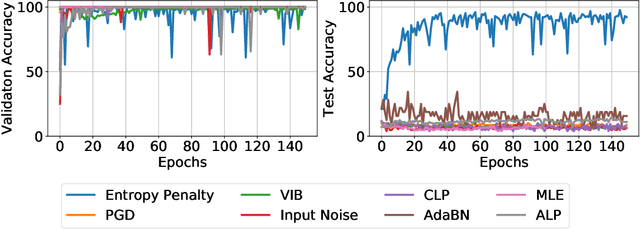
It has been shown that instead of learning actual object features, deep networks tend to exploit non-robust (spurious) discriminative features that are shared between training and test sets. Therefore, while they achieve state of the art performance on such test sets, they achieve poor generalization on out of distribution (OOD) samples where the IID (independent, identical distribution) assumption breaks and the distribution of non-robust features shifts. Through theoretical and empirical analysis, we show that this happens because maximum likelihood training (without appropriate regularization) leads the model to depend on all the correlations (including spurious ones) present between inputs and targets in the dataset. We then show evidence that the information bottleneck (IB) principle can address this problem. To do so, we propose a regularization approach based on IB, called Entropy Penalty, that reduces the model's dependence on spurious features-- features corresponding to such spurious correlations. This allows deep networks trained with Entropy Penalty to generalize well even under distribution shift of spurious features. As a controlled test-bed for evaluating our claim, we train deep networks with Entropy Penalty on a colored MNIST (C-MNIST) dataset and show that it is able to generalize well on vanilla MNIST, MNIST-M and SVHN datasets in addition to an OOD version of C-MNIST itself. The baseline regularization methods we compare against fail to generalize on this test-bed. Our code is available at https://github.com/salesforce/EntropyPenalty.