 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbeddings for DNN speaker adaptive training
Paper and Code
Sep 30, 2019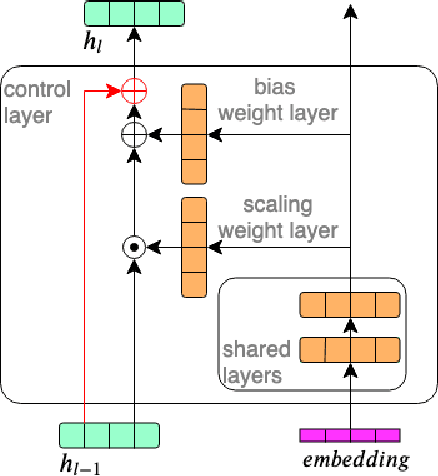
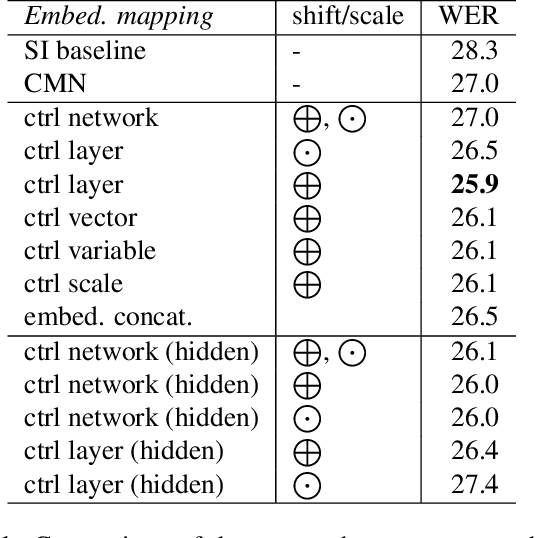
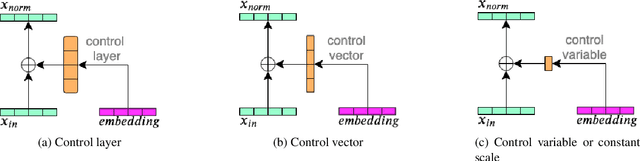
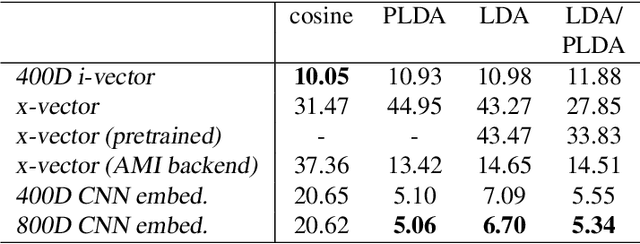
In this work, we investigate the use of embeddings for speaker-adaptive training of DNNs (DNN-SAT) focusing on a small amount of adaptation data per speaker. DNN-SAT can be viewed as learning a mapping from each embedding to transformation parameters that are applied to the shared parameters of the DNN. We investigate different approaches to applying these transformations, and find that with a good training strategy, a multi-layer adaptation network applied to all hidden layers is no more effective than a single linear layer acting on the embeddings to transform the input features. In the second part of our work, we evaluate different embeddings (i-vectors, x-vectors and deep CNN embeddings) in an additional speaker recognition task in order to gain insight into what should characterize an embedding for DNN-SAT. We find the performance for speaker recognition of a given representation is not correlated with its ASR performance; in fact, ability to capture more speech attributes than just speaker identity was the most important characteristic of the embeddings for efficient DNN-SAT ASR. Our best models achieved relative WER gains of 4% and 9% over DNN baselines using speaker-level cepstral mean normalisation (CMN), and a fully speaker-independent model, respectively.