 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudent Specialization in Deep ReLU Networks With Finite Width and Input Dimension
Paper and Code
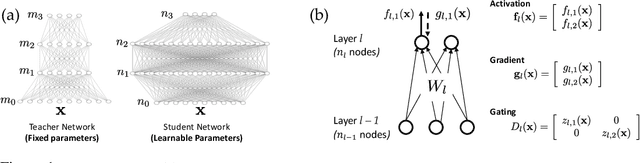
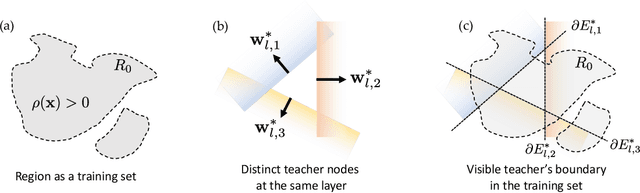
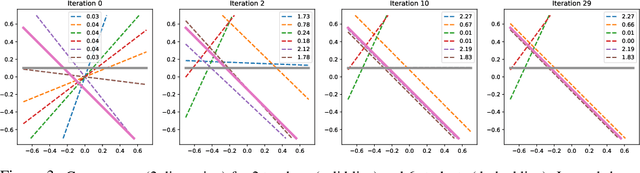
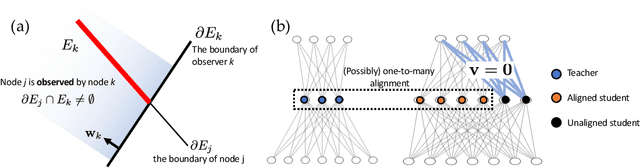
In this paper, we adopt a student-teacher setting to analyze the phenomenon of student specialization, when both teacher and student are deep ReLU networks and student is over-realized (i.e., more student nodes than teacher at each layer). In such a setting, the student network learns from the output of a fixed teacher network of the same depth with Stochastic Gradient Descent (SGD). Our contributions are two-fold. First, we prove that when the gradient is small at every training sample, student nodes \emph{specialize} to teacher nodes in the lowest layer under mild conditions. Second, analysis of noisy recovery and training dynamics in 2-layer network shows that strong teacher nodes (with large fan-out weights) are specialized by student first and weak ones are left unlearned until late stage of training. As a result, it could take a long time to converge into these small-gradient critical points. Our analysis shows that over-realization is an important factor to enable specialization at the critical points, and helps more student nodes specialize to teacher nodes with fewer iterations. Different from Neural Tangent Kernel and statistical mechanics approach, our approach operates on finite width, mild degrees of over-realization and finite input dimension. Experiments justify our finding. The code is released in https://github.com/facebookresearch/luckmatters.