 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Observations Using a Single Video Demonstration and Human Feedback
Paper and Code
Sep 29, 2019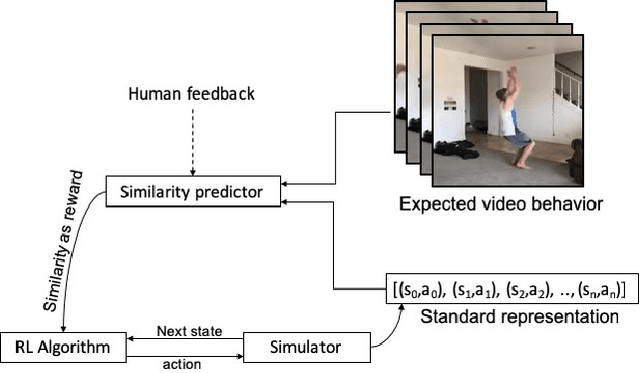
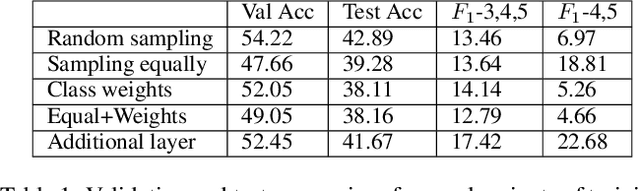
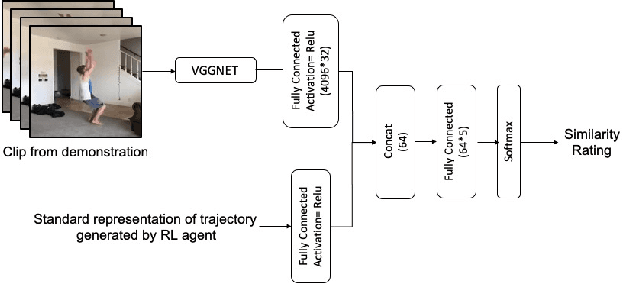
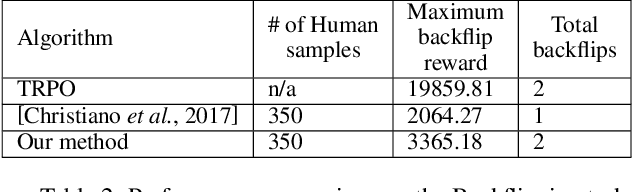
In this paper, we present a method for learning from video demonstrations by using human feedback to construct a mapping between the standard representation of the agent and the visual representation of the demonstration. In this way, we leverage the advantages of both these representations, i.e., we learn the policy using standard state representations, but are able to specify the expected behavior using video demonstration. We train an autonomous agent using a single video demonstration and use human feedback (using numerical similarity rating) to map the standard representation to the visual representation with a neural network. We show the effectiveness of our method by teaching a hopper agent in the MuJoCo to perform a backflip using a single video demonstration generated in MuJoCo as well as from a real-world YouTube video of a person performing a backflip. Additionally, we show that our method can transfer to new tasks, such as hopping, with very little human feedback.